「机器学习-李宏毅」:Deep Learning-Introduction
这篇文章中,介绍了Deep Learning的一般步骤。
Up and downs of Deep Learning
1958: Perceptron (linear model)
1969: Perceptron has limitation
1980s: Multi-layer perceptron
Do not have significant difference from DNN today
1986: Backpropagation
Usually more than 3 hidden layers is not helpful
1989: 1 hidden layer is “good enough”, why deep?
2006: RBM initialization (breakthrough)
2009: GPU
2011: Start to be popular in speech recognition【语音辨识】
2012: win ILSVRC image competition 【图像识别】
Step 1: Neural Network
在将Regression 和 Classification时,Step 1 是确定一个function set。
在Deep Learning中,也是相同的,只是这里的function set就是一个neural network的结构。
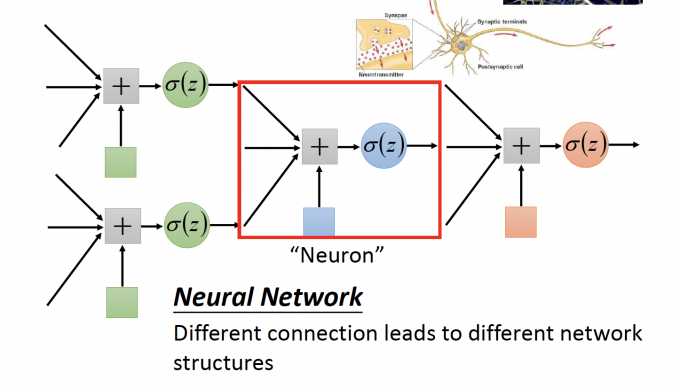
上图中,一个Neuron就是如上图所示的一个unit,neuron之间不同的连接方式构成不同的Neural Network。
Fully Connect Feedforward Network
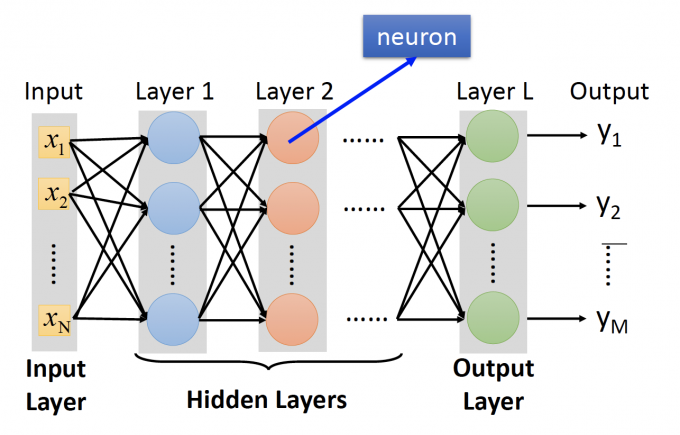
这是一个Fully Connect Feedforward Network【全连接反馈网络】,其中每个neuron的activation function都是一个sigmod函数。
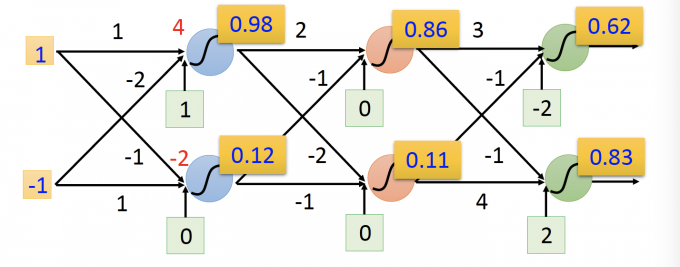
为什么说neural network其实就是一个function呢?上面两张图中,输入是一个vector,输出也是一个vector,可以用下面函数来表示。
$$ f\left(\left[\begin{array}{c}1 \\ -1\end{array}\right]\right)=\left[\begin{array}{c}0.62 \\ 0.83\end{array}\right] f\left(\left[\begin{array}{l}0 \\ 0\end{array}\right]\right)=\left[\begin{array}{l}0.51 \\ 0.85\end{array}\right] $$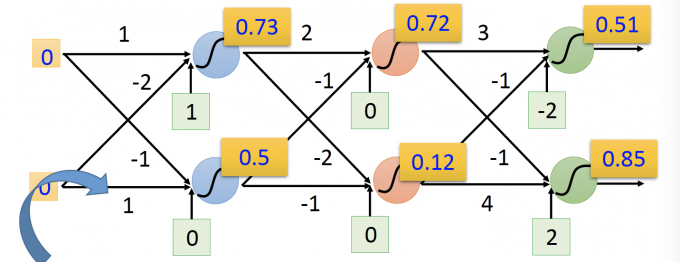
上图为全连接网络的一般形式,第一层是Input Layer,最后一层是Output Layer,中间的其他层称为Hidden Layer。
而Deep Learning中的Deep的含义就是Many hidden layers的意思。
Matrix Operation
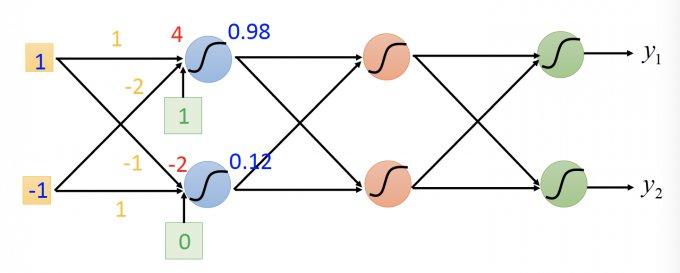
上图的全连接网络中,第一个hidden layer的输出可以写成矩阵和向量的形式:
$$ \sigma\left(\left[\begin{array}{cc}1 & -2 \\ -1 & 1\end{array}\right]\left[\begin{array}{c}1 \\ -1\end{array}\right]+\left[\begin{array}{c}1 \\ 0\end{array}\right]\right)=\left[\begin{array}{c}0.98 \\ 0.12\end{array}\right] $$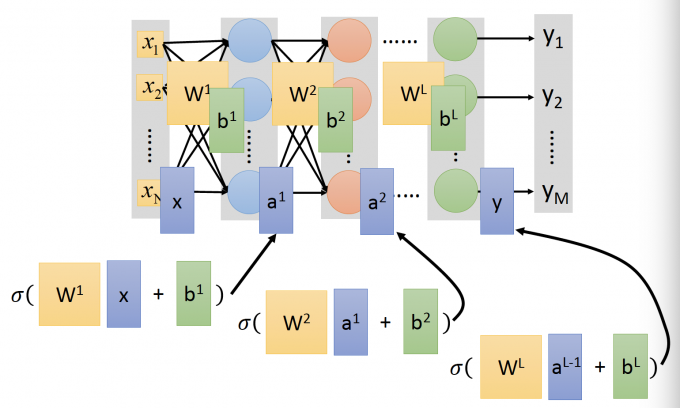
更为一般的公式,用W表示权重,b代表bias,a表示hidden layer的输出。输出vector y可以写成 $y = f(x)$ 的形式,即: $y= f(x)=$

转换为矩阵运算的形式,就可以使用并行计算的硬件技术(GPU)来加速矩阵运算,这也是为什么用GPU来训练Neural Network 更快的原因。
Output Layer
在 Logistic Regression中第4节讲到Logistic Regression有局限,消除局限的一种方法是Feature Transformation。
但是Feature Transformation需要人工设计,不太“机器学习”。
在下图全连接图中,把Output Layer换成一个Multi-class Classifier(SoftMax),而其中Hidden Layers的作用就是Feature extractor,从feature x提取出新的feature,也就是 output layer的输入。
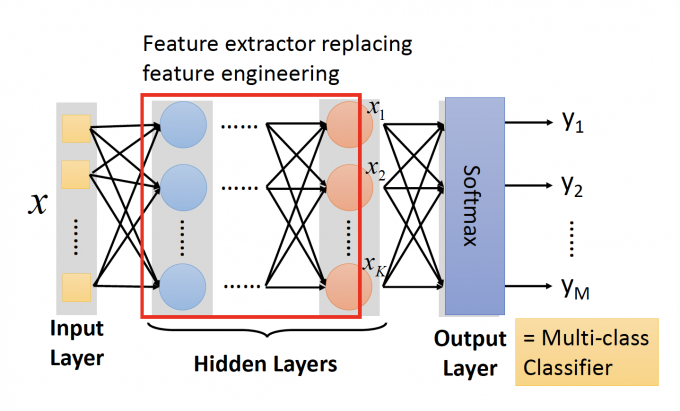
这样就不需要人工设计Feature Transformation/Feature engineering,可以让机器自己学习:如何将原来的feature转换为更好分类的feature。
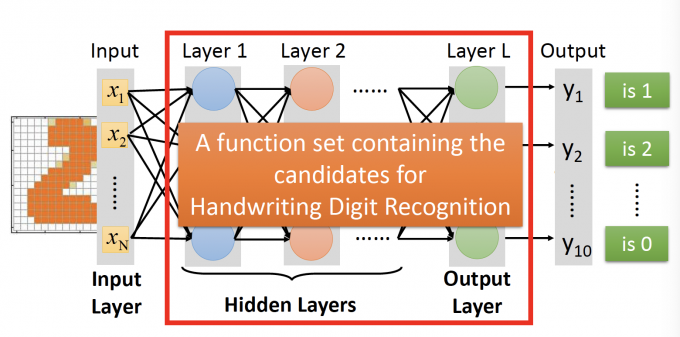
Handwriting Digit Recognition
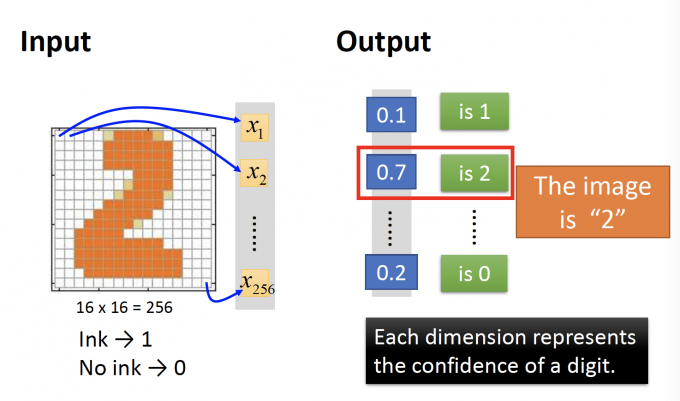
在手写数字辨别中,输出是一个16*16的image(256维的vector),输出是一个10维的vector,每一维表示是该image是某个数字的概率。
在手写数字辨别中,需要设计neural network的结构来提取输入的256维feature。
Step 2: Goodness of function
之前我们已经使用过的最小二乘法和交叉熵作为损失函数。
一般在Neural Network中,使用output vector 和target vector的交叉熵作为Loss。
Step 3: Pick the best function
在NN中,也使用Gradient Descent。

但是,Deep Neural Network中,参数太多了,计算结构也很复杂。
Backpropagation:an efficient way to compute $\partial{L}/\partial{w}$ in neural network.
Backpropagation本质也是Gradient Descent,只是一种更高效进行Gradient Descent的算法。
在很多 toolkit(TensorFlow,PyTorch ,Caffe等)中都实现了Backpropgation。
Backpropagation部分,见下一篇博客。
Reference
「机器学习-李宏毅」:Deep Learning-Introduction

