「Paper Reading」:AFL++:Combine Incremental Steps of Fuzzing Research
今天给大家分享的论文是一篇基于AFL的工作:AFL++:Combine Incremental Steps of Fuzzing Research,发表在USENIX Workshop。分享时的slides
目录
Introduction
Fuzzing已经成为软件测试强有力的工具,通过大量的非预期的输入,检测软件的运行状态,以发现软件的隐藏性漏洞。
而AFL是最具盛名的fuzzing工具,基于AFL的研究也层出不穷,但这些技术往往是正交式、独立地发展。
因此:
- 将这些前沿新颖的fuzzing技术结合起来是一件很困难的事情
- 而评估这些不同维度的fuzzing技术也是一件很困难的事
AFL++这个工作就致力于解决这个问题:
- AFL++提供了一个可用的fuzzing工具,结合了许多前沿fuzzing技术
- AFL++还提供了一种新颖的可自定义的变异API(Custom Mutator API),研究人员能够轻松将自己设计的Mutator应用到AFL++上,或和其他Mutators结合起来。
- 这篇论文还评估了许多结合起来的fuzzing技术组合,评估结果体现了fuzzing技术的target-dependency.
State-of-the-Art
在正式介绍AFL++ 之前,很有必要介绍一下afl++结合的其他fuzzing技术。
除了AFL的主要特点,afl++主要结合了三方面的技术,分别是:
调度上的。包括AFLFast的种子调度和MOpt的变异调度。
绕过fuzzing中的一些roadblocks,包括LAF- Intel和Red Queen。
针对一些复杂的结构化输入的变异。
AFL
首先介绍一下AFL的工作原理和主要特征。
AFL是一种基于覆盖率反馈(coverage- guided)的fuzz工具。
AFL的工作流程如图所示:
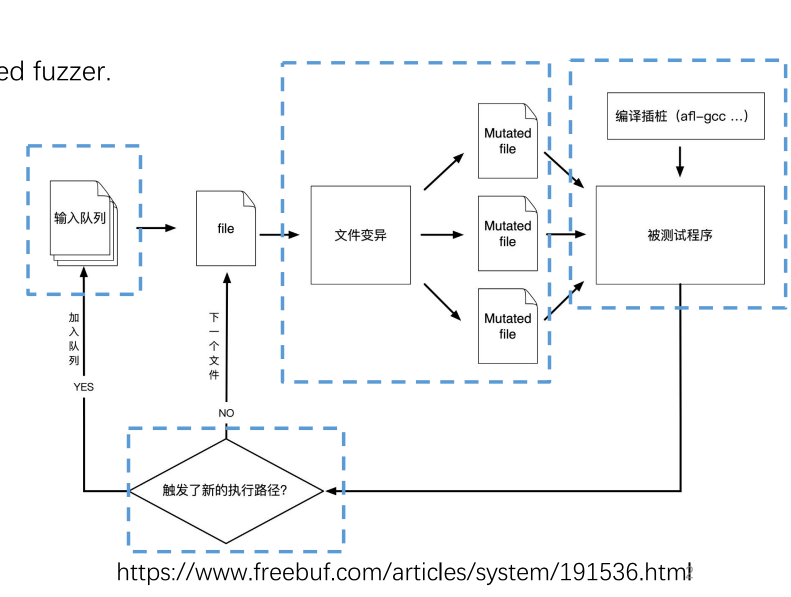
- 编译时对源码进行插桩,以记录代码覆盖率(Code Coverage)
- 初始化一些输入文件,加入到输入队列(queue)
- 在队列中按照一定策略选择种子(seed),并进行大量的突变(mutation),得到大量的变异文件
- 如果该变异文件触发了新的执行路径,则将其保存下来,加入到队列中。
- goto 2
上述过程会一直进行下去,其中触发的crash会被记录下来,以便后面分析程序漏洞。
Coverage Guided Feedback
AFL是一种使用边覆盖率作为反馈的灰盒fuzzer。
什么是边覆盖率呢?
在介绍边覆盖率之前,先介绍一下块覆盖率:
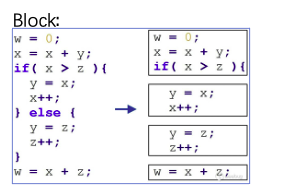
如上图,将一个程序划分为一个一个的程序块,一个程序块中的指令要么都执行,要么都不执行。
将上述程序拖到IDA中,得到下图,因此可以用程序块之间的跳转表示边。所以
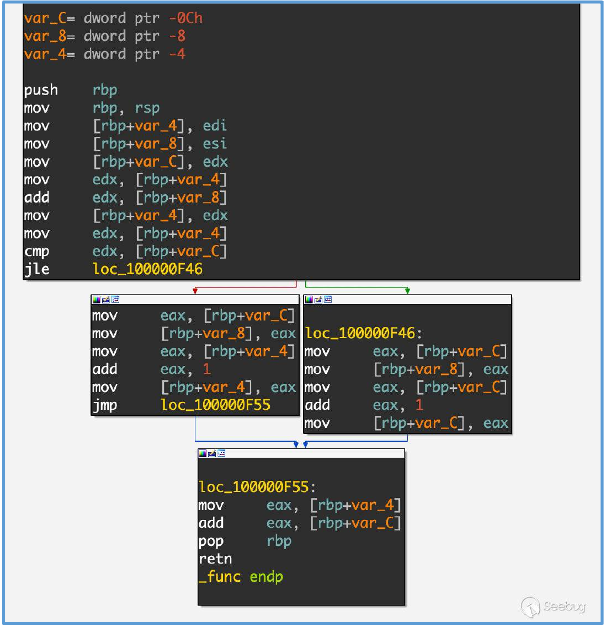
A -> B -> C -> D -> E (tuples: AB, BC, CD, DE)
A -> B -> D -> C -> E (tuples: AB, BD, DC, CE)
这两条执行路径的覆盖率不同。
实现上,就是给每一个块分配一个编译随机值,通过上一个块和当前块的运算的值来表示该边,再进行统计。
Mutation
AFL中的Mutation主要分为两种,一种是deterministic stage,从下表的变异中选择一个mutation进行连续变异。
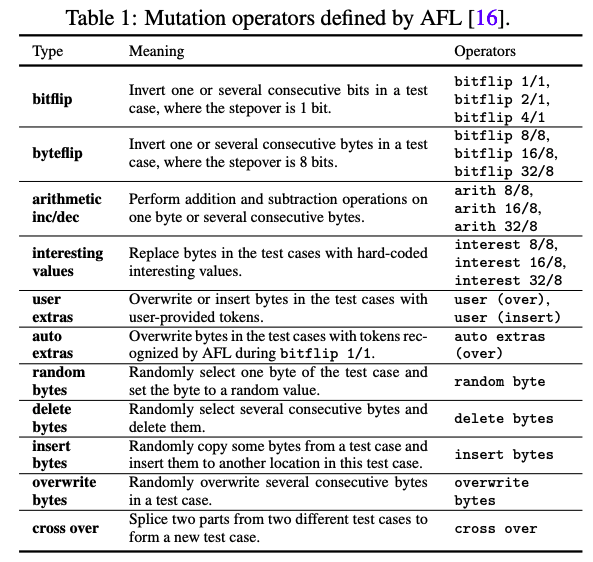
而havoc stage 则是每次选择一堆变异,工作作用在seed上。
Fork Server
由于AFL会大量运行目标程序,因此为了减少fuzzer的执行开销,AFL使用了一种forkserver的技术。
forkserver的工作原理如下图所示:
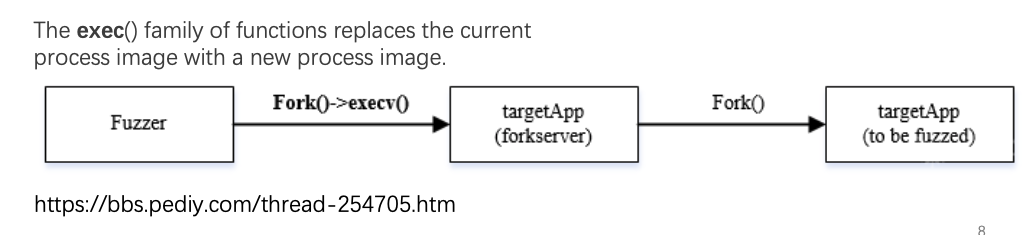
当fuzzer在执行目标程序前,会先执行fork()命令,得到一个子进程。
子进程再通过execv()指令执行目标程序,而execv()命令有一个很特别的地方,他会用这个目标程序的映像覆盖掉子进程的映像。
因此,此时的fuzzer fork()出的子进程就变成了插过桩的目标程序,也就是forkserver。
The exec() family of functions replaces the current process image with a new process image.
当fuzzer想要执行目标程序时,就和forkserver通信,将fork目标程序的任务交给forkserver,这样就极大的提高了fuzzer的执行效率。
Persistent Mode
AFL另一个提高效率的功能是Persistent Mode。
使用Persistent Mode,只需要对程序做一点小小的改动,即对程序patch一个循环,就像这样:

Persistent Mode允许单个进程重复输入,极大减少了fork的开销。
Smart Scheduling
AFLFast
基于AFL的另一个改进领域是调度问题,一个是种子调度,如何选种子的问题;另一个是变异调度,如何选mutation的问题。
AFLFast主要是从种子调度的方向改进AFL。
AFLFast观察到种子大多数生成的输入都经历了相同的高频路径,因此想要设计一些策略能够focus on一些低频路径。
因此,AFLFast设计了两种策略:
Search Strategy:关于在队列中如何选种子的问题,决定种子挑选顺序。
Power Schedule:关于选出的种子可以被fuzz多少次,即可以生成多少变异文件,而这个数量被定义为种子的energy。
seed’s energy: the amount of generated inputs from each seed
AFL
其实在AFL中也有相应的策略,我们先来看AFL中的种子策略是这样的:
如何挑选种子:
在AFL中,
update_bitmap_score函数中维护了一个变量fav_factor,这个值越小意味值种子越favored,而这个值其实是由程序的执行时间(exec_us)和种子的长度(len)决定的。
如何给种子分配energy:
在AFL中,
calculate_score函数中维护了一个变量perf_score,这个值越大意味着会给种子分配更多的energy,这个种子就有更多的机会被fuzz,而这个值主要由执行时间(exec_us)、程序的执行路(bitmap_size)、发现该种子的困难度(handicap)以及种子的深度(depth)共同决定的。
其中handicap,困难度,可以这样来理解,这个值越大,说明发现这个种子经过了很长轮数,来之不易,所以希望能更focus on在这些来之不易的种子上。
AFLFast
而AFLFast中,不管是决定如何挑选种子,还是觉得如何给种子分配energy,AFLFast都还考虑了另外两个变量。
对每个种子,定义两个变量:
一个是f(i) ,表示该种子被fuzz的总次数,也叫做频率。
另一个是s(i) ,表示该种子在队列挑选中,被挑选了多少次。
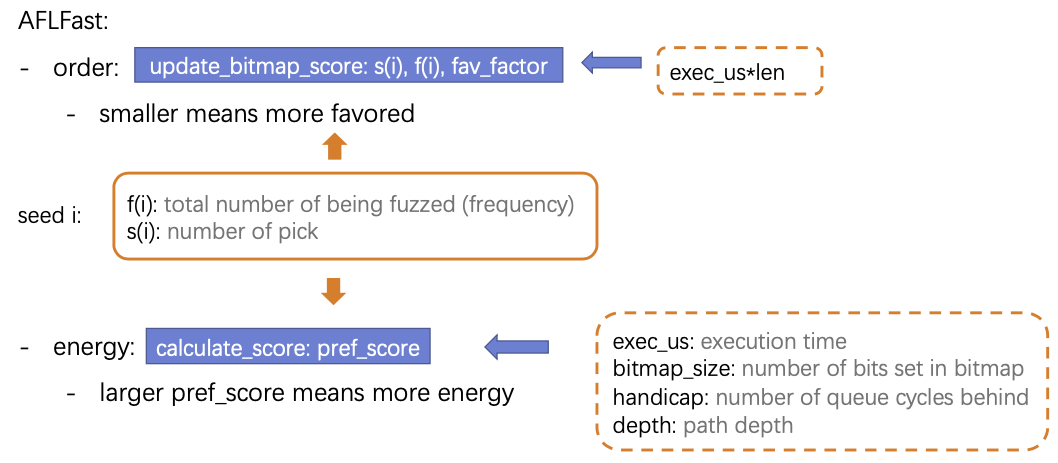
AFLFast-Power Schedule
这里主要介绍一下AFLFast的Power Schedule:
AFLFast提供了6中Power Schedule:
定义p(i)为分配的energy。
EXPLOIT:p(i) = AFL
EXPLOIT模式下的power schedule,就是之前提到的AFL的原生策略。
EXPLORE:p(i) = AFL / const
EXPLORE模式下,对AFL中计算出的energy除以了一个常数。
看这样的一个例子:

程序需要依次匹配到这些字符,才可以找到crash。
如果规定每个种子的energy是一个常数,即p = $2^{16}$ ,那总共分配 $2^{18}$ 的energy才能找到crash。

但如果把这个种子的转移过程用马尔可夫链建模,可以发现如果从
b***转移到ba**,fuzz的转移概率为 $2^{-10}$ (从4个字符中选择一个字节,每个字节有 $2^{8}$ 中情况)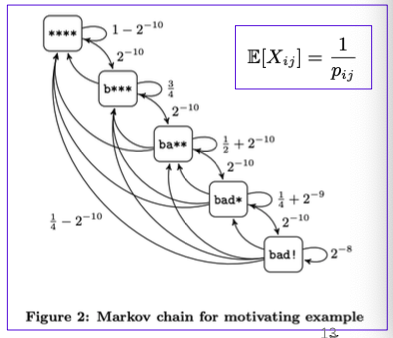
因此,可以得到从
i种子转移到j种子需要的energy的期望是 $E[X_{ij}]=\frac{1}{p_{ij}}$那么找到
bad!状态,所需要的总energy的期望和为 : $E[X_{01}]+E[X_{12}]+E[X_{23}]+E[X_{34}]=4 \cdot 2^{10}=4k$因此,我们总是分配所需期望energy更多的值,所以在AFLFast模式,会对energy除以一个常数。
剩下这四种策略都是从不同的方式抑制高频边被fuzz。

MOpt
与种子调度相对的是变异调度,MOpt这个工作就是从变异调度的角度提升fuzz的效率。
MOpt工作的主要贡献有:
首先是观察到:很多有效的变异如bitflip,执行的时间却很少。
论文中统计了在deterministic stage不同变异产生的interesting test cases的数量,发现bitlip表现优异。
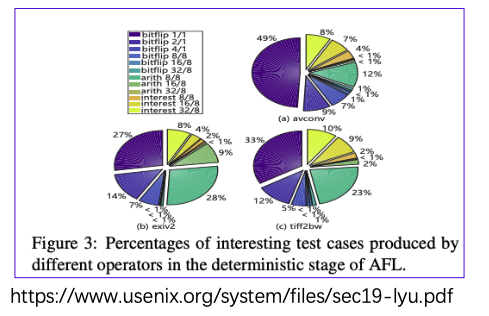
但从变异执行时间的角度,发现这些变异效率高的变异,执行时间比较短。
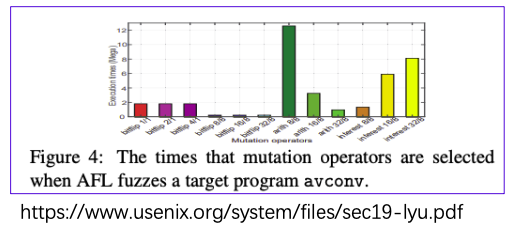
所以MOpt的motivation是:希望能花更多的时间在那些变异效率高的变异上。
PSO
MOpt使用粒子群优化算法来对问题建模。
定义粒子(particle),即变异(mutation)。粒子的位置,就是该变异被选择的概率。
每一个粒子群(swarm),则是所有mutations的概率分布。
而MOpt与原始PSO算法不同,MOpt使用的是多个群(multiple swarms),每一个群都是一个概率分布。
在MOpt的工作流程中,主要有两个核心模块。
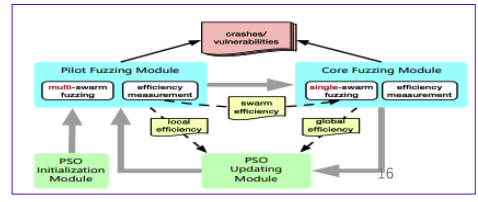
一个是Pilot模块,另一个是Core模块。
Pilot模块:评估每一个粒子群,也就是该mutations的概率分布的fuzz效率。
Core模块:使用Pilot模块评估出的效率最高的mutation策略 来fuzz。
Bypassing Roadblocks
fuzzing中有时会遇到一些roadblocks。
LAF- Intel
LAF-Intel解决的fuzzing中遇到的一些困难比较语句,如下图:

即使当输入为0xabad1dee时,已经非常接近正确答案了,fuzzer也会认为他是错误的。
因此LAF- Intel的思路是,把这些比较难的、比较一连串字符的比较划分为 多个单字节的比较。
这样可以让程序块的划分粒度更细,当你每匹配到一个字节时,就被认为是interesting,被保存到队列中,以后可以继续fuzz,这样,fuzzer就可以一步一步的解决这个roadblock。
另外,LAF-Intel是基于LLVM架构的,所以LAF- Intel实现了三种Pass:
- The split-compares-pass:划分为单字节比较,并全部转换为<, >, ==, !=和无符号数的比较。
- The compare-transform-pass:重写了strcmp和memcmp,将其全部转换为单字节比较。
- The split-switches-pass:将switch比较转换为单字节比较的if串。
RedQueen
RedQueen解决的roadblocks:
magic number:和上文LAF-Intel解决的roadblocks类似。

nested checksum:而校验和/嵌套校验和的情况就像下图所示:

代码如下图所绘:

RedQueen这篇工作的贡献是:
首先他观察到种子的输入,有时是和程序的运行状态直接相关的,这种关联定义为Input-to-State联系。
比如下图:
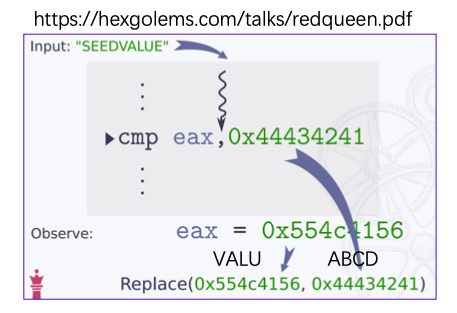
hook住cmp指令,运行时,观察到eax的值为VALU ,与之比较的值为ABCD(都是小端序)。
而VALU在输入中也有出现,所以这里观察到的VALU大概率就是输入的VALU,如果能将输入的VALU换成ABCD,就有较大可能绕过这个roadblock。
RedQueen就是利用这样的Input-to-State的关系来解决这些roadblocks。
Magic Bytes
解决Magic Bytes的方法就是上文提到的那样,希望能找到一系列的可替换对。
具体流程为:
- 跟踪:将所有的cmp指令hook住,尝试运行一下,把指令比较的操作数都提取出来。
- 变化:对比较指令的操作数做变异操作,比如加一或减一的操作,因为从该条指令并不能得到源码中的比较关系,源码的比较逻辑可能是大于、小于等。
- 编码:对得到的替换对进行编码操作,如小端序、hex、base-64等,像刚刚的例子就是小端序的编码。
- 应用:将得到的这些替换对< pattern -> repl >应用到输入中,即在输入中找pattern,替换为repl,试运行。
在执行上述流程之前,RedQueen执行了一个操作,该操作极大提高了绕过的效率。
如果替换对为(0x00, 0x04),并且输入文件像下面左图这样:
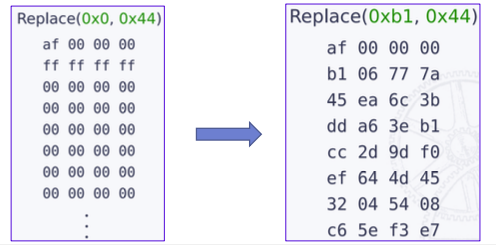
输入文件中出现大量的0x00,就像产生了碰撞一样,其实很多位置并不和那条程序指令相关,这样就会花费大量时间。
如果输入是像上图右边这样的,比较colorful,那RedQueen的效率就会很高。
所以RedQueen在进行绕过之前,会对输入做染色(Colorization)的操作,在保证种子执行路径不变的情况下,增大输入的熵值。
Nested Checksum
而对checksum的绕过,这其实是一件很难的事情,因此RedQueen会选择先忽略掉这些困难,后面再来修正。
具体操作:
对输入进行染色
根据指定条件,识别这些像checksum比较的指令,hook住。
然后就用
cmp al, alpatch原程序,这样就让这些checksum的判断一定为正。
但这样的patch就会带来false positive,即这些输入的执行路径可能并不是这样的。
RedQueen就会在之后进行输入验证,并修复他们。
在fix阶段,其实就是用magic bytes的方法,对checksum的位置进行替换。
不过如果对于嵌套的校验和指令,就需要按照拓扑序(Topological Sort),一个一个的fix。
Mutate Structure Inputs:AFLSmart
对于输入复杂的、结构性强的程序,fuzzer通常会生成大量的无效输入。
因此AFLSmart将AFL和Peach结合起来,AFLSmart的输入为Peach pits格式,一种xml文件。
AFLSmart 将种子都表示为Peach pits格式,这样,就可以基于这些块进行变异,而不需要基于比特级的 变异。

AFL++
AFL++就将上述提到的诸多fuzzing技术都结合在一起,并提供了一种可供扩展的API。
Seed Scheduling
AFL++的Seed Scheduling就是基于AFLFast的种子调度。
AFL++的Power Schedules除了AFLFast提到的6种,还有另外两种,Mmopt和Rare。
Mmopt主要关注那些最新发现的种子
而Rare主要关注那些具有罕见边的种子。

Mutators
AFL++集成了许多mutator,包括RedQueen的Input-to-State mutator,包括Mopt mutator。
因此,AFL++就像一个框架,提供了一个自定义的mutator接口规范,实现这些接口,就可以将自己的mutator缝合到AFL++上,或者将不同的mutator缝合在一起。
AFL++除了提供了mutator的接口规范,还提供了trimming的借口规范。
Input-To-State Mutator
这个mutator是基于RedQueen的input-to-state.
这里主要介绍他和RedQueen不同的地方:
- Colorization
- RedQueen在染色时是保持程序执行路径不变,即hash of bitmap不变。
- 而AFL++除了保持程序的执行路径不变,还对程序的执行时间做了一定控制,规定了程序的执行时间下界为2x slowdown
- Bypass Comparison
- AFL++采用的是一种probabilistic fuzzing。即如果这个roadblock,使用替换的方法,或者修复的方法失败了,那fuzzer下一次就会以较小概率尝试绕过他。(当下解决不了的困难,先放一放zzzz)
- 不过其实RedQueen中也有相应的设计,RedQueen是使用的虚拟机断点hook cmp指令。因此,如果这个断电被hit的次数比较少,就将这个断点去掉。
- CmpLog Instrumentation
- RedQueen中采用的是虚拟机断点hook的cmp指令,当断点被hit时,再提取指令操作数。
- 而AFL++则是使用的一种共享表,每一个指令都记录他的前256次执行的操作数。
MOpt
AFL++中也缝合了MOpt的Pilot和Core模块。
并且可以和Input-to-State结合。
Instrumentation
在插桩上,AFL++首先解决了边hit count溢出的问题。
因为在AFL中,边只会记录到255。
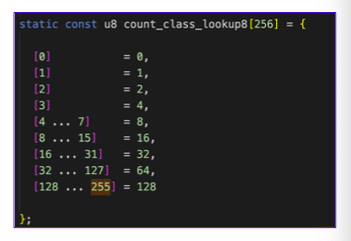
有两种方法可以解决:
- NeverZero,加一个进位标志。NeverZero可以提高fuzzer的表现性能。
- Saturated Counters:当计数超过255时,就停在255。这个做法,不推荐,反而会让fuzzer的性能变差。
除了使用NeverZero,AFL++还使用了Ngram优化边覆盖率的统计。
AFL原生的统计边覆盖率的代码是:
1 | cur_location = <COMPILE_TIME_RANDOM>; |
AFL只考虑了上一个基本块和当前基本块,这样的计算速度更快,但会带来更多的碰撞。
而Ngram则是考虑当前基本块和前N-1个基本块表示该边,这样能部分碰撞,实验结果也表明Ngram能提高实验的性能。
AFL++实现了多种后端的插桩,具体实现的区别如下:

Evaluation
略,具体可见slides 。
Reference
「Paper Reading」:AFL++:Combine Incremental Steps of Fuzzing Research

