「LeetCode」:Array
8月某司实训+准备开学期末考,我可太咕了q w q…dbq,(希望)高产博主我.我..又回来了。
LeetCode Array专题,持久更新。(GitHub)
Array
27-Remove Elements
Solution
1 | from typing import List |
Python的参数传递和函数返回值:
1
def removeElement(self, nums:List[int], val:int) -> int:
题目要求:
“remove all instances of that value in-place and return the new length.”
“Do not allocate extra space for another array, you must do this by modifying the input array in-place with O(1) extra memory.”
“Confused why the returned value is an integer but your answer is an array?
Note that the input array is passed in by reference, which means modification to the input array will be known to the caller as well.”
题目要求是在原数组上删除数值,不能额外开新的空间存储数组。
意思就是说,虽然函数返回的是一个数值,但实际返回答案是一个数组。
因为数组的传递是指针传递,返回的是数组长度,则相当于返回了这个in-place的新数组。
26-Remove Duplicates from Sorted Array
26-Remove Duplicates from Sorted Array
Solution:
1 | from typing import List |
第一次提交的时候
before = nums[0] - 1报错了,原因是传入数组长度为0,下标越界。注意空数组的下标越界问题。
80-Remove Duplicates from Sorted Array II
80-Remove Duplicates from Sorted Array II
Solution:
1 | from typing import List |
189-Rotate Array(S123)
Problem:
简述题目大意,给一个列表nums,一个 $k$ 值,要求原址让列表循环右移 $k$ 位。
Solution:
其实以下三种做法时间空间复杂度差别不大,主要看个思路吧。
| S | Runtime | Memory | Language |
|---|---|---|---|
| S1 | 64ms | 15.2MB | pyhon3 |
| S2 | 64ms | 15.1MB | python3 |
| S3 | 116ms | 15.1MB | python3 |
S1-简单做法:空间换时间
时间复杂度:$\mathcal{O}(n)$
空间复杂度:$\mathcal{O}(n)$ ,循环右移时多开了一个数组。
1 | from typing import List |
S2-利用数学同余关系
时间复杂度:$\mathcal{O}(n)$
空间复杂度:$\mathcal{O}(n)$ ,循环右移时只多开了一个变量。
原理:
定理[1]:
设 $m$ 是正整数,整数 $a$ 满足 $(a,m)=1$ ,$b$ 是任意整数。若 $x$ 遍历模 $m$ 的一个完全剩余系,则 $ax+b$ 也遍历模 $m$ 的一个完全剩余系。
由以上定理可以得知,设 $n$ 为列表长度, $x$ 是列表的下标,遍历 $n$ 的一个完全剩余系。
如果 $(k,n)=1$ , $kx$ 也遍历 $n$ 的一个完全剩余系。这种情况,列表下标通过 $k$ 的倍数的顺序连成一个环。
:只需要额外一个变量 $temp$ 存储移动占用的值。
如果 $(k,n)\neq 1$ ,那么 $kx$ 不会遍历一个 $n$ 的完全剩余系,会出现下图的情况(如绿色的线的元素的 $idx = kx+0$ ,红色线的元素都是 $idx=kx+1$ ),会在 $k$ 的某个剩余类一直循环。
:遍历每个 $k$ 的剩余类。 在每次循环移位时,需要记录该次循环的起始位,防止重复。
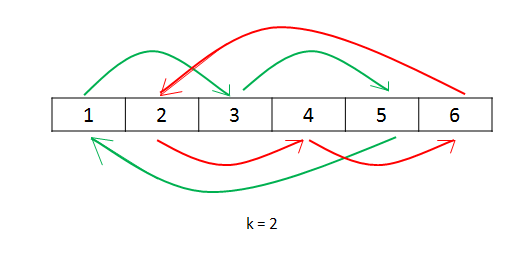
1 | class Solution: |
S3-利用反转列表的思路
时间复杂度:$\mathcal{O}(n)$
空间复杂度:$\mathcal{O}(n)$
原理:
1 | Original List : 1 2 3 4 5 6 7 |
1 | from typing import List |
Python用引用管理对象。
1
2int a1 = 1, *p = &a1;
int a2 = 2, &b = a2;- 指针:指针变量是一个新变量,这个变量存储的是(变量a1的)地址,该地址指向一个存储单元。(该存储单元存放的是a1的值)。
- 引用:引用的实质是变量的别名,所以a2和b实际是一个东西,在内存中占有同一个存储单元。
所以python中交换对象可以直接
a,b = b,aPython 列表的操作:切片。
41-First Missing Positive
Solution:
排一下序,维护一个expect变量就行了。
时间复杂度:$\mathcal{O}(n\log{n})$ ,题目没有卡常。
Runtime: 36 ms, faster than 70.96% of Python3 online submissions for First Missing Positive.
空间复杂度:$\mathcal{O}(n)$
Memory Usage: 13.8 MB, less than 69.19% of Python3 online submissions for First Missing Positive.
1 | from typing import List |
299-Bulls and Cows
Problem:
题目大意是:给定两个相同长度的字符串,计算这两个字符串有多少个对应位数字相同,和多少个位置不对应但数字相同的个数。
Solution:
应用字符0-9本身数字的性质。
时间复杂度:$\mathcal{O}(n)$
空间复杂度:$\mathcal{O}(n)$
1 | class Solution: |
ord()函数和chr()函数
ord()返回字符的ASCII码,chr函数返回ASCII码对应的字符。
浅析lambda表达式,匿名函数,类似于C语言的宏。
格式:
lambda [arg1[, arg2,...]] : expression双变量同时遍历使用zip()函数
134-Gas Station(S12)
Problem:
题目大意是:有N个环形加油站,每个加油站能加油gas[i],一个汽车起始油量为0,且从i个站开到第i+1个站需要花费cost[i]的油量。找出这个车能顺时针跑完一圈的起始点(如果有,则唯一),如果不能返回-1。
Solution:
| Solution | Runtime | Memory | Language |
|---|---|---|---|
| S1-简单做法 | 3244ms | 14.9MB | python3 |
| S2-原理优化 | 104ms | 14.8MB | python3 |
S1-简单解法
时间复杂度:$\mathcal{O}(n^2)$ ,实际远达不到 $n^2$ ,算有一点贪心叭。
空间复杂度:$\mathcal{O}(n)$
该汽车从起点i能跑完的必要条件:
起始点
gas[i] - cost[i] >= 0。并且维护一个数组存放gas[i] - cost[i],即这个站自给自足的油量余量。如果从满足条件1的起点开始跑一圈, 要求路程中的油量必须大于等于0。维护一个汽车当前总油量 $S$ (用前缀和维护),每跑过一段路程,都要求 $S>=0$ 。
1 | from typing import List |
S2-对问题分析进行再简化
时间复杂度:$\mathcal{O}(n)$
空间复杂度:$\mathcal{O}(n)$
1 | i : 0 1 2 3 4 |
如果 $S=\sum_{i=0}^{n-1} g[i]-c[i],S<0$ 那么一定无解, $S$ 称为总积累油量。
如果 $S>=0$,如果有找出最优解的方法,则一定有解。
起点满足 $g[i]-c[i]>=0$ ,把这些点称为正余量点。
用 $\mathcal{O}(1)$ 算出从第 $i$ 个点出发到第 $n$ (n就是第0个点) 个点所积累的油量: $res[i] =S-sum[i-1]$ .即用总积累油量减去前 $i-1$ 段路程能积累的油量(一般积累为负)。(sum数组就是 g-c的前缀和)
对于满足起点要求 $g[i]-c[i]>=0$ 的所有点,计算从第 $i$ 个点出发到第 $n$ 个点到油量积累。那么有最大油量积累的点即为最优起始点。(题目规定如果存在,则点唯一)
因此,因为 $S$ 固定,只需要找到 $sum$ 数组中的最小值的下标,下标+1即是结果。
- 证明其正确性:
- 如果满足 $g[i]-c[i]>=0$ 的上述点 $i,j(i<j)$ ,如果 $res[i]>=res[j]$ ,说明从 $i$ 到 $j$ 是正油量积累,贪心的思想,那肯定积累的油量越多越好, $i$ 比 $j$ 优。
- 如果 $res[i]<=res[j]$ ,说明从 $i$ 到 $j$ 是负油量积累,如果从 $i$ 点出发,到 $j$ 点就负油量了;如果从 $j$ 点出发,该车最后再跑 $i$ 到$j$ 段,因为保证了总积累油量是正,所以最后一定有足够的油量能跑完 $i$ 到 $j$ 段。
- 再证只要 $S>=0$ 则一定有解。是动态尝试起始点,( $i,j$ 都满足 $g[i]-c[i]>=0$ )从点 $i$ 开始,跑到点 $j$ 时,如果该途中途有出现油量不够,那就把 $i$ 到 $j$ 的这段路程放到路途的后面来跑,等油量积累够了再跑这段。
Code:
1 | from typing import List |
- 前缀和
list.index(value)找出list中值为value的第一个下标。min(list)返回list中的最小值。
118-Pascal’s Triangle
Problem:
给定一个数字,输出如下规则的值。
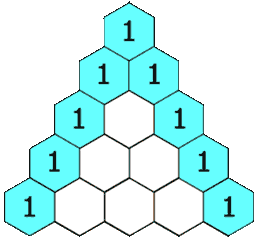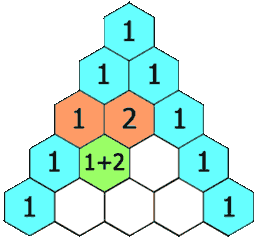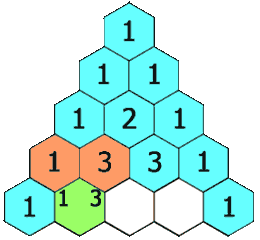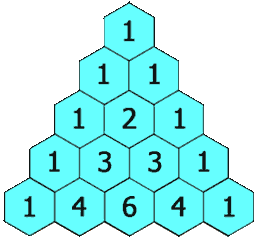
Solution:
注意边界吧。(不太喜欢这种题qwq
1 | from typing import List |
Python 中的append会出现值被覆盖的情况:变量在循环外定义,但在循环中对该变量做出一定改变,然后append到列表,最后发现列表中的值都是一样的。
因为Python中很多时候都是以对象的形式管理对象,因此append给列表的是一个地址。
119-Pascal’s Triangle II
Problem:
给定一个数字,输出某一行。
Solution:
1 | from typing import List |
169-Majority Element
Problem:
给一串数字,找到出现次数大于 n/2 的数字。
Solution:
用字典计数。
1 | from typing import List |
- 返回值最大/最小的键/索引。
- 列表:
- 最大值的索引:list.index(max(list))
- 最小值的索引:list.index(min(list))
- 字典:
- 最大值的键:max(dict, key=dict.get)
- 最小值的键:min(dict, key=dict.get)
- 列表:
229-Majority Element II
Problem:
给一串数字,返回出现次数大于 n/3 的数字。
Solution:
1 | from typing import List |
字典的实用方法:
操作 实现方法 删除字典元素 del dict['Name']清空字典所有条目 dict.clear()删除字典 del dict返回指定键的值,如果值不存在返回default的值 dict.get(key, default)如果键不存在字典中,添加键并将值设为default,于get类似 dict.setdefault(key, default=None)判读键是否存在 1. if k in dict2.dict.has_key(key)存在返回true以列表返回可遍历的(键,值)元祖数组 dict.items()以列表返回一个字典的所有键 dict.keys()以列表返回字典中的所有值 dict.values()返回最大值的键值 max(dict, key=dict.get)返回最小值的键值 min(dict, key=dict.get)遍历字典的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# -*- coding:utf-8 -*-
dict={"a":"Alice","b":"Bruce","J":"Jack"}
# 实例一:键循环
for i in dict:
print "dict[%s]=" % i,dict[i]
# 结果:
# dict[a]= Alice
# dict[J]= Jack
# dict[b]= Bruce
# 实例二:键值元组循环
for i in dict.items():
print i
# 结果:
# ('a', 'Alice')
# ('J', 'Jack')
# ('b', 'Bruce')
# 实例三:键值元组循环
for (k,v) in dict.items():
print "dict[%s]=" % k,v
# 结果:
# dict[a]= Alice
# dict[J]= Jack
# dict[b]= Bruce
274-H-Index
Problem:
给出研究人员论文的论文引用次数,计算它的H指数(有h篇论文的引用次数至少为h,剩下N-h篇论文的引用次数不超过h)。
Solution:
时间复杂度:$\mathcal{O}(n\log{n})$
空间复杂度:$\mathcal{O}(n)$
排序后,再二分。(感觉自己的二分写的有点丑qwq
还有一种思路是,排序完,从最大的h开始递减遍历,满足条件就返回。反正排序也要$\mathcal{O}(n\log{n})$ 的复杂度…
1 | from typing import List |
- 非递归写二分:
while begin <= end
275-H-Index II
Problem:
和274一样,给了递增的论文引用数,希望能用指数时间返回H指数。
Solution:
啊,就二分鸭。
1 | from typing import List |
243-Shortest Word Distance
qwq 这道题还收费来着,于是于是就开了个中国区的会员(中国区的会员便宜好多啊!!)
Problem:
给定一串单词,单词1和单词2,计算单词1单词2在单词列表中的距离。
Solution:
| Solution | Runtime | Memory | Language |
|---|---|---|---|
| S1-二分查找 | 44ms | 15.7MB | python3 |
| S2-线性维护 | 40ms | 15.6MB | python3 |
S1-二分查找
时间复杂度:$\mathcal{O}(n\log{n})$
空间复杂度:$\mathcal{O}(n)$
(最开始还很疑惑啥是单词距离…单词1和单词2可能在单词列表中重复出现)
计算出单词1和单词2在单词列表中出现的索引值列表,是递增有序的。
对于单词1索引列表中的每个值,在单词2索引列表中查找该值的lower_bound,计算距离。
同理,对于单词2索引列表中的每个值,也同样计算距离。
找出最小距离。
1 | from typing import List |
S2-线性维护:
时间复杂度:$\mathcal{O}(n)$
空间复杂度:$\mathcal{O}(n)$
问题还能再简化,线性扫描单词列表,维护两个变量,单词1出现的最近索引,单词2出现的最近索引。扫描时计算距离,每当单词1或单词2出现时,就用另一个单词的最近索引计算。
1 | from typing import List |
C++中:
lower_bound(begin, end, num):返回num的下界,即大于等于num的第一个索引位置。
upper_bound(begin, end, num):返回num的上界,即大于num的第一个索引位置。
Python中用二分实现这两个函数。
244-Shortest Word Distance II
Problem:
和上题题干类似,计算单词距离,但是此问是每一个单词列表,可能有多个询问。
Solution:
对每一个单词列表,都可能有多个询问。
因此,之前243的解法每次询问都会遍历一遍单词列表。如果对每个单词列表询问数为 $M$ ,那么时间复杂度为 $\mathcal{O}(NM)$ ,会超时,所以希望能将单词列表的有关信息存下来,再用常数时间处理每一个询问。
这里的解法是用一个字典把每个单词出现的index列表存下来,键是单词,值是index列表。这个列表相对于单词列表的数目应该是远远小于的,因此用二重循环应该也能过吧(没有尝试二重循环解法)
这里有两种思路,一种是自己想的归并思路,还有一种是官方解答的思路,官方思路比归并的思路更优雅一些,问题抽象的更好。(代码差距不大,时间差距也不太大)
| Solution | Runtime | Memory | Language |
|---|---|---|---|
| S1-归并思路查询 | 96ms | 20.8MB | python3 |
| S2-交叉跳跃查询 | 80ms | 20.4MB | python3 |
双指针:$i$ 指向列表1,$j$指向列表2.
S1-归并思路
归并思路:列表的值都是有序的,再把两个列表的值按归并的思想再排序,可以想成把点一个一个有序放在数轴上。
$i$指针前进的情况:(排序时,取列表1的下一个数字)
- $i+1<len1$ and $li1[i+1] < li[j]$
- $i+1<len1$ and $li1[i+1] < li[j+1]$
- $i+1 < len1$ and $j+1 == len2$ ($j$ 已无法移动)
其余情况:$j$ 移动。
1 | from typing import List |
S2-交叉比较
对于当前指向列表1和列表2的两个元素 $li1[i]$ 和 $li2[j]$ ,对 $li1[i]$来说,只需要和旁边的属于列表2的元素比较,对 $li2[j]$ 同理。
因此,当 $li1[i]>li2[j]$ 时,下一次的比较应该让 $j$ 指针前移一位,继续计算指针 $i$ 所指元素和其旁边的列表2的元素。同理,当 $li1[i]<li2[j]$ 时,下一次的比较应该让 $i$ 指针前移一位,继续计算指针 $j$ 和其旁边的列表1的元素。
具体移动如下图。
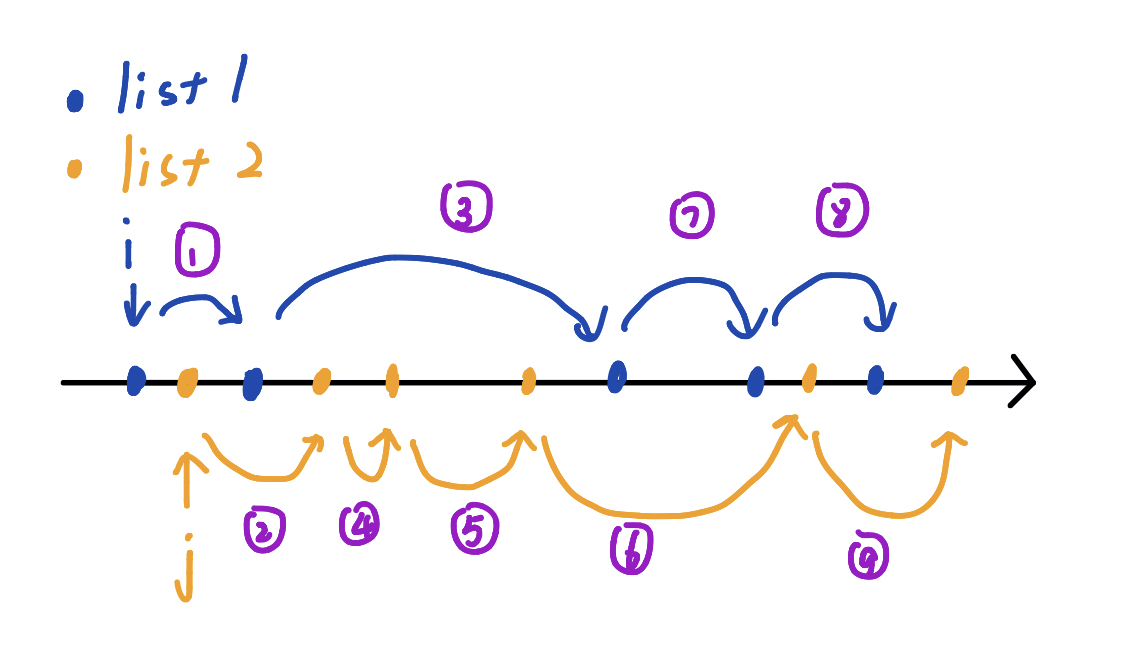
1 | from typing import List |
277-Find the Celebrity
Problem:
已有know(i, j) API,判断i是否知道j,i是名人的充要条件是其他所有人知道i,而i不知道其他所有人。
Solution:
两种思路,第一种较为直观,使用二重循环,但剪枝多,远达不到 $\mathcal{O}(n^2)$ ,第二种稍做优化。因此两种解法差距不太大。
| 提交时间 | 运行时间 | 内存消耗 | 语言 |
|---|---|---|---|
| S几秒前 | 1896ms | 13.6MB | python3 |
| 5 分钟前 | 1772ms | 13.6MB | python3 |
S1-直观思路
时间复杂度:远不到 $\mathcal{O}(n^2)$
用了二重循环,但剪枝很多,所以远达不到 $\mathcal{O}(n^2)$
1 | class Solution: |
S2-排除法
时间复杂度:$\mathcal{O}(n)$
排除i:根据know(i, j)=True 可以认为i不是名人,j可能是名人。
对于n-1个关系,最后从n个人中选出一个可能的人,再根据名人的充要条件去判断他是否是名人。
1 | class Solution: |
245-Shortest Word Distance III
245-Shortest Word Distance III
Problem:
题意增加了两个单词可能相同,分两种情况就好了。
Solution:
1 | from typing import List |
217-Contains Duplicate[E]
Problem:
判断数组中有无重复元素出现。
Solution:
1 | class Solution: |
219-Contains Duplicate II[E]
Problem:
判断数组中是否有两个相同的值,他们的索引之差小于等于k。
Solution:
存放出现该值的最近的索引,扫一遍。
1 | class Solution: |
4-Median of Two Sorted Arrays[H] (2S)
4-Median of Two Sorted Arrays[H]
Problem:
给两个排好序的数组,返回一个中位数
Solution:
| S | 运行时间 | 内存消耗 |
|---|---|---|
| S1 | $\mathcal{O}(m+n)$ :92ms | 14.3MB |
| S2 | $\mathcal{O}(\log(m+n))$ :52ms | 13.3MB |
S1:
归并排序的做法。
时间复杂度:$\mathcal{O}(m+n)$
1 | from typing import List |
S2:
二分的思路
时间复杂度:$\mathcal{O}(\log(m+n))$
一、首先讨论一个数组的中位数,数组有n个元素,如果n为奇数,则第(n+1)/2个是中位数;如果n为偶数,则第(n+1)/2和第(n+2)/2的平均值为中位数。
回到本题,因为是两个数组,如果根据奇偶性分类讨论就过于麻烦了,所以将两种情况统一以简化解题思路。
即无论n是奇数还是偶数,数组的中位数都是第(n+1)/2和第(n+2)/2的平均数。
回到本题,设数组1有n个元素,数组2有m个元素,则中位数为两个数组的有序序列的第(n+m+1)/2个和第(n+m+2)/2个的平均数。
二、因此,题目需要求解的问题改为求这两个有序数组的有序序列的第k个数。
二分思想:两个数组分别找第k/2个数,(假设都存在),比较,如果第一个数组的这个数小于第二个数组,说明第k个数肯定不在第一个数组的前k/2个数中,因此就可以直接去掉数组1的前k/2个元素,查找有序序列的第k-k/2个数;同理,如果大于,则说明第k个数肯定不在第二个数组的前k/2个数中,去掉数组2的前k/2个元素。
使用一个数组起始指针l1和l2来实现数组的“去掉”前k/2个元素。
设数组1的元素个数为n,数组2的元素个数为m。
递归函数Find(l1, l2, k):查找起始指针为l1, l2的两个有序数组的第k个数。
讨论边界情况,有数组为空的情况。即
l1 == n或者l2 == m.如果第一个数组已为空,则直接返回第二个数组的第k个数;
同理,如果第二个数组为空,则直接返回第一个数组的第k个数。
两个数组都不为空的情况。即
l1 < n或者l2 < m.递归边界:
k == 1,即返回nums1[l1]和nums2[l2]中较小的那一个。数组长度边界:即有数组的剩余元素个数小于
k/2,那么拿出来比较的就应该是数组的最后一个元素。维护两个值
k1和k2来分别表示用两个数组的第 k1和k2个来比较。(k1 k2都小于等于k/2)
1
2
3# to avoid the rest length of nums1/nums2 is shorter than k//2
k1 = k//2 if l1+k//2 <= n else n-l1
k2 = k//2 if l2+k//2 <= m else m-l2比较
nums1[l1+k1-1]和nums2[l2+k2-1]的大小,递归:相等:
如果
k-k1-k2 == 0说明nums1的前k1个和nums2的前k2个就是有序序列的前k个,返回nums1[l1+k1-1]。否则,(即某一个数组的剩余长度小于k/2),分别去掉两个数组的前k1和k2个数,递归调用 Find(l1+k1, l2+k2, k-k1-k2) 。
nums1[l1+k1-1] > nums2[l2+k2-1]说明可以去掉数组2的前k2个数,递归调用 Find(l1, l2+k2, k-k2)
nums1[l1+k1-1] > nums2[l2+k2-1]说明可以去掉数组1的前k1个数,递归调用 Find(l1+k1, l2, k-k1)
Code:
1 | class Solution: |
reference
- 《信息安全数学基础》 2.2同余类和剩余系。
「LeetCode」:Array

