「机器学习-李宏毅」:HW1-Predict PM2.5
在本篇文章中,用手刻Adagrad完成了「机器学习-李宏毅」的HW1-预测PM2.5的作业。其中包括对数据的处理,训练模型,预测,并使用sklearn toolkit的结果进行比较。
有关HW1的相关数据、源代码、预测结果等,欢迎光临小透明的GitHub
Task Description
从中央气象局网站下载的真实观测资料,必须利用linear regression或其他方法预测PM2.5的值。
观测记录被分为train set 和 test set, 前者是每个月前20天所有资料;后者是从剩下的资料中随机取样出来的。
train.csv: 每个月前20天的完整资料。
test.csv: 从剩下的10天资料中取出240笔资料,每一笔资料都有连续9小时的观测数据,必须以此观测出第十小时的PM2.5.
Process Data
train data如下图,每18行是一天24小时的数据,每个月取了前20天(时间上是连续的小时)。

test data 如下图,每18行是一笔连续9小时的数据,共240笔数据。

最大化training data size
每连续10小时的数据都是train set的data。为了得到更多的data,应该把每一天连起来。即下图这种效果:
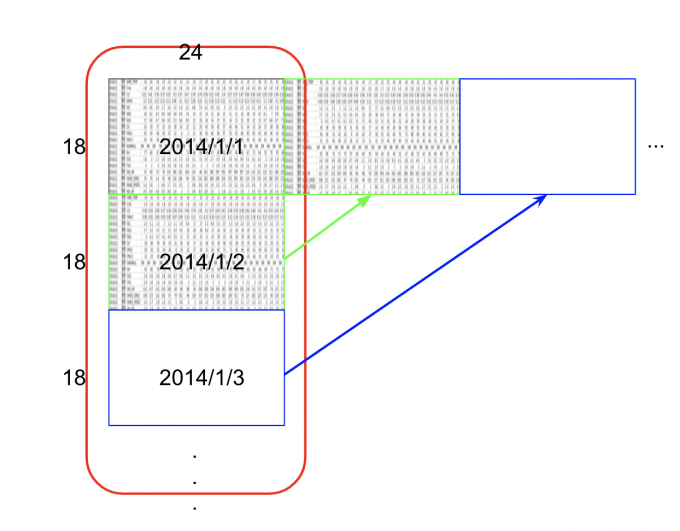
每个月就有: $20*24-9=471$ 笔data
1
2
3
4
5
6
7
8
9# Dictionary: key:month value:month data
month_data = {}
# make data timeline continuous
for month in range(12):
temp = np.empty(shape=(18, 20*24))
for day in range(20):
temp[:, day*24: (day+1)*24] = data[(month*20+day)*18: (month*20+day+1)*18, :]
month_data[month] = temp筛选需要的Features :
这里,我就只考虑前9小时的PM2.5,当然还可以考虑和PM2.5等相关的氮氧化物等feature。
training data
1
2
3
4
5
6
7# x_data v1: only consider PM2.5
x_data = np.empty(shape=(12*471, 9))
y_data = np.empty(shape=(12*471, 1))
for month in range(12):
for i in range(471):
x_data[month*471+i][:] = month_data[month][9][i: i+9]
y_data[month*471+i] = month_data[month][9][i+9]testing data
1
2
3
4
5# Testing data features
test_x = np.empty(shape=(240, 9))
for day in range(240):
test_x[day, :] = test_data[18*day+9, :]
test_x = np.concatenate((np.ones(shape=(240, 1)), test_x), axis=1)Normalization
1
2
3
4
5
6
7
8
9
10
11
12# feature scale: normalization
mean = np.mean(x_data, axis=0)
std = np.std(x_data, axis=0)
for i in range(x_data.shape[0]):
for j in range(x_data.shape[1]):
if std[j] != 0:
x_data[i][j] = (x_data[i][j] - mean[j]) / std[j]
for i in range(test_data.shape[0]):
for j in range(test_data.shape[1]):
if std[j] != 0:
test_data[i][j] = (test_data[i][j] - mean[j])/std[j]
Training
手刻Adagrad 进行training。(挖坑:RMSprop、Adam[1]
Linear Pseudo code
1 | Declare weight vector, initial lr ,and # of iteration |
其中的矩阵操作时,注意求gradient时矩阵的维度。可参考下图。
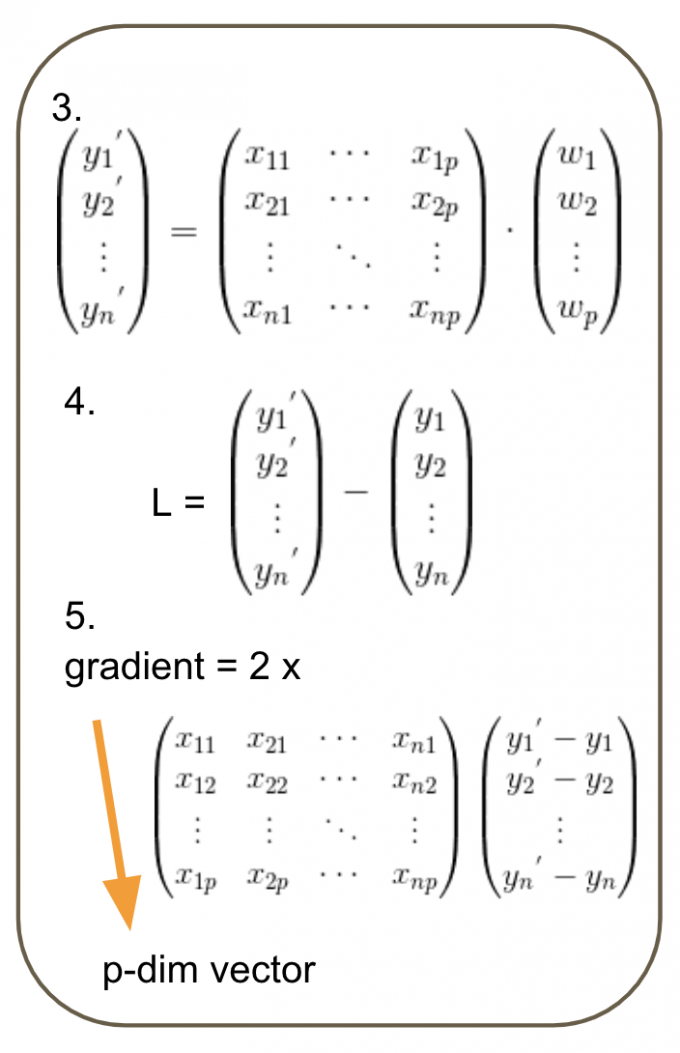
Adagrad Pseudo code
1 | Declare weight vector, initial lr ,and # of iteration |
注:代码实现时,将bias存在w[0]处,x_data的第0列全1。因为w和b可以一同更新。(当然,也可以分开更新)
Adagrad training
1 | # train-adagrad |
Testing
1 | answer = np.dot(test_x, w) |
Draw and Analysis
在每次迭代更新时,我将Loss的值存了下来,以便可视化Loss的变化和更新速度。
Loss的变化如下图:(红色的是sklearn toolkit的loss结果)
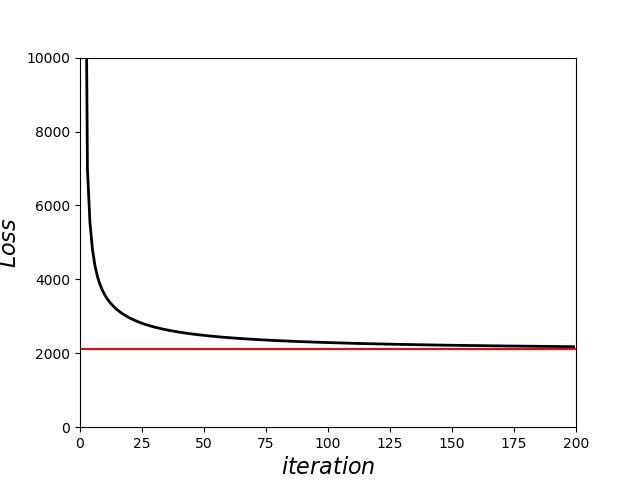
此外,在源代码中,使用sklearn toolkit来比较结果。
结果如下:
1 | v1: only consider PM2.5 |
发现参数有一定差异,于是我在testing时,也把sklearn的结果进行预测比较。
一部分结果如下:
1 | ['id', 'value', 'sk_value'] |
Code
有关HW1的相关数据、源代码、预测结果等,欢迎光临小透明的GitHub
1 | ######################### |
Reference
- 待完成
「机器学习-李宏毅」:HW1-Predict PM2.5

