「算法导论」:排序-总结
本篇文章review了算法中的排序算法,包括冒泡排序、插入排序、归并排序、堆排序(以及用堆实现优先队列)、快速排序和计数排序。
分别从算法思路、算法伪代码实现、算法流程、算法时间复杂度四个方面阐述每个算法。
排序
排序问题:
输入:一个 $n$个数的序列 $<a_1,a_1,…,a_n>$
输出:输入序列的一个重拍 $<a_1’,a_2’,…,a_n’>$ ,使得 $a_1’\leq a_2’ \leq…\leq a_n’$ .
在实际中,待排序的数很少是单独的数值,它们通常是一组数据,称为记录(record)。每个记录中包含一个关键字(key),这就是需要排序的值。记录剩下的数据部分称为卫星数据(satellite data),通常和关键字一同存取。
原址排序:输入数组中仅有常数个元素需要在排序过程中存储在数组之外。
典型的原址排序有:插入排序、堆排序、快速排序。
符号说明:
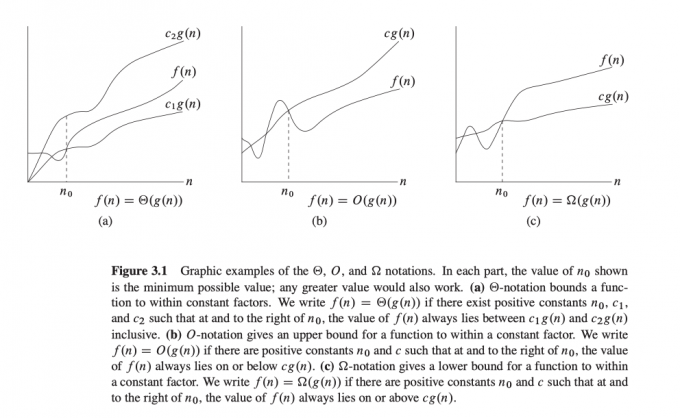
$\Theta$ 记号:
$\Theta$ 记号渐进给出一个函数的上界和下界。
$\Theta(g(n))=\left\{f(n): \text { there exist positive constants } c_{1}, c_{2}, \text { and } n_{0}\text { such that } \right. \left.0 \leq c_{1} g(n) \leq f(n) \leq c_{2} g(n) \text { for all } n \geq n_{0}\right\}$$g(n)$ 称为 $f(n)$ 的一个渐进紧确界(asymptotically tight bound)
$O$ 记号
$O$ 记号只给出了函数的渐进上界。
$O(g(n))=\left\{f(n): \text { there exist positive constants } c \text { and } n_{0}\text { such that } \right. \left.0 \leq f(n) \leq c g(n) \text { for all } n \geq n_{0}\right\}$$\Omega$ 记号
$\Omega$ 记号给出了函数的渐进下界。
$\Omega(g(n))=\left\{f(n): \text { there exist positive constants } c \text { and } n_{0}\text { such that } \right. \left.0 \leq c g(n) \leq f(n) \text { for all } n \geq n_{0}\right\}$符号比较如下图:
排序算法运行时间一览 :
| 算法 | 最坏情况运行时间 | 平均情况/期望运行时间 |
|---|---|---|
| 插入排序 | $\Theta (n^2)$ | $\Theta(n^2)$ |
| 归并排序 | $\Theta(n\lg{n})$ | $\Theta(n\lg{n})$ |
| 堆排序 | $O(n\lg{n})$ | - |
| 快速排序 | $\Theta(n^2)$ | $\Theta(n\lg{n})$ (expected) |
| 计数排序 | $\Theta(k+n)$ | $\Theta(k+n)$ |
| 基数排序 | $\Theta(d(n+k))$ | $\Theta(d(n+k))$ |
| 桶排序 | $\Theta(n^2)$ | $\Theta(n)$ (average-case) |
冒泡排序
反复交互相邻未按次序排列的元素。
BUBBLESORT(A)
- 参数:A待排序数组
1 | for i = 1 to A.lengh-1 |
冒泡排序是原址排序,流行但低效。
插入排序
如下图所示,插入排序就像打牌时排序一手扑克牌。

- 开始时,我们的左手为空,桌子上的牌面向下。
- 然后,我们每次从桌子上拿走一张牌,想把它放在左手中的正确位置。
- 为了找到这张牌的正确位置,我们从右到左将这张牌和左手里的牌依次比较,放入正确的位置。
- 左手都是已排序好的牌。
INSERTION-SORT(A)
- A:待排序数组
1 | for j = 2 to A.length |
插入排序是原址排序,对于少量元素是一个有效的算法。
最坏情况的运行时间: $\Theta(n^2)$ .
归并排序
分治
分治: 将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。
分治的步骤:
- 分解:分解原问题为若干规模较小的子问题。
- 解决:递归地求解各子问题,规模较小,可直接求解。
- 合并:合并这些子问题的解成原问题的解。
算法核心
归并排序中的分治 :
- 分解:分解待排序的n个元素序列成各n/2个元素序列的两个子序列。
- 解决:使用归并排序递归地排序两个子序列,当序列长度为1时,递归到达尽头。
- 合并:合并两个已经排序好的子序列以产生排序好的原序列。
核心 :合并两个已经排序好的子序列——MERGE(A, p, q, r)
- A: 待排序原数组。
- p, q, r: 数组下标,满足 $p\leq q<r$ 。
- 假设子数组 A[p..q] 和A[q+1..r]都已经排好序,合并这两个数组代替原来的A[p..r]子数组。
MERGE算法理解:
- 牌桌上有两堆牌面朝上,每堆都已排好序,最小的牌在顶上。希望将两堆牌合并成排序好的输出牌堆,且牌面朝下。
- 比较两堆牌顶顶牌,选取较小的那张,牌面朝下的放在输出牌堆。
- 重复步骤2直至某一牌堆为空。
- 将剩下的另一堆牌面朝下放在输出堆。
MERGE合并的过程如下图所示:
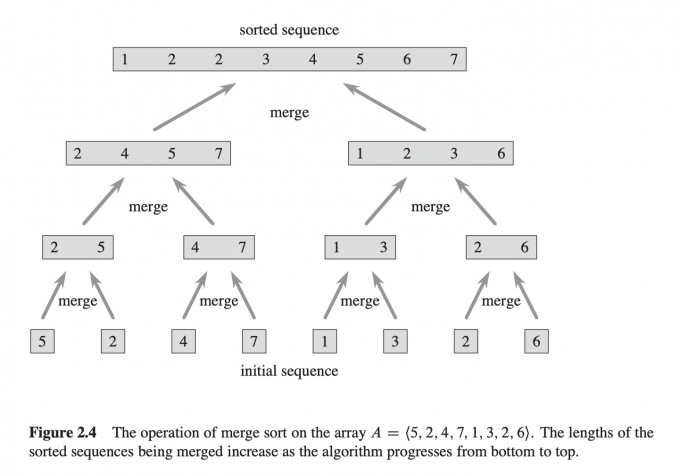
MERGE算法分析:
在上述过程中,n个元素,我们最多执行n个步骤,所以MERGE合并需要 $\Theta(n)$ 的时间。
伪代码
MERGE(A, p, q, r)
- 功能:合并已排序好的子数组A[p..q]和A[q+1..r]
- 参数:A为待排序数组,p, q, r为数组下标,且满足 $p\leq q<r$
1 | Let S[p..r] be new arrays |
MERGE-SORT(A, p, r)
- 功能:排序子数组A[p..r]
1 | if p < r |
算法分析
分治算法运行时间分析
分治算法运行时间递归式来自三个部分。
假设 $T(n)$ 是规模为 $n$ 的一个问题的运行时间。若规模问题足够小,则直接求解需要常量时间,将其写作 $\Theta(1)$ 。
假设把原问题分解成 $a$ 个子问题,每个子问题的规模是原问题的 $1/b$ (在归并排序中, $a$ 和 $b$ 都为2,但很多分治算法中 $a\neq b$ )。为了求解一个规模为 $n/b$ 规模的子问题,需要 $T(n/b)$ 的时间,所以需要 $aT(n/b)$ 的时间求解 $a$ 个子问题。
如果分解子问题需要 $D(n)$ 时间,合并子问题需要 $C(n)$ 时间。
递归式:
$$ T(n)=\left\{\begin{array}{ll}\Theta(1) & \text { if } n \leq c \\ a T(n / b)+D(n)+C(n) & \text { otherwise }\end{array}\right. $$归并排序分析
前文分析了MERGE(A, p, q, r) 合并两个子数组的时间复杂度是 $\Theta(n)$ ,即 $C(n)=\Theta(n)$ ,且 $D(n)=\Theta(n)$ .
归并排序的最坏情况运行时间 $T(n)$ :
$$ T(n)=\left\{\begin{array}{ll}\Theta(1) & \text { if } n=1 \\ 2 T(n / 2)+\Theta(n) & \text { if } n>1\end{array}\right. $$用递归树的思想求解递归式:
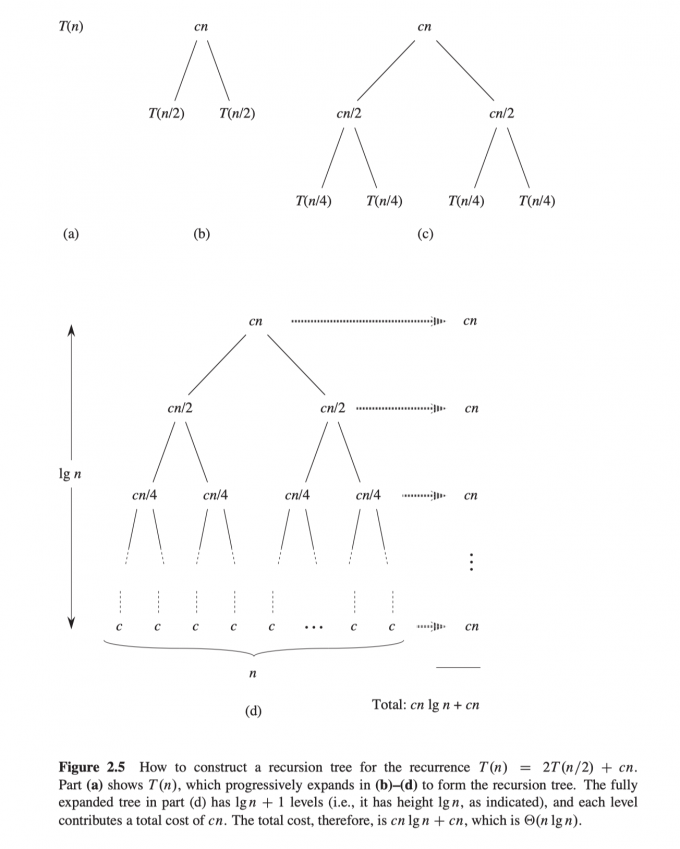
即递归树每层的代价为 $\Theta(n)=cn$ ,共有 $\lg{n}+1$ 层,所以归并排序的运行时间结果是 $\Theta(n\lg{n})$ .
堆排序
堆
自由树 :连通的、无环的无向图。
有根数 :是一棵自由树,其顶点存在一个与其他顶点不同的顶点,称为树的根。
度 :有根树中一个结点 $x$ 孩子的数目称为 $x$ 的度。
深度 :从根 $r$ 到结点 $x$ 的简单路径。
二叉树 :不包括任何结点,或者包括三个不相交的结点集合:一个根结点,一棵称为左子树的二叉树和一棵称为右子树的二叉树。
完全k叉树 :所有叶结点深度相同,且所有内部结点度为k的k叉树。
(二叉)堆 :是一个数组,它可以被看成一个近似的完全二叉树,树上的每个结点对应数组中的一个元素。除了最底层外,该树被完全填满,并且是从左到右填充。如下图所示。
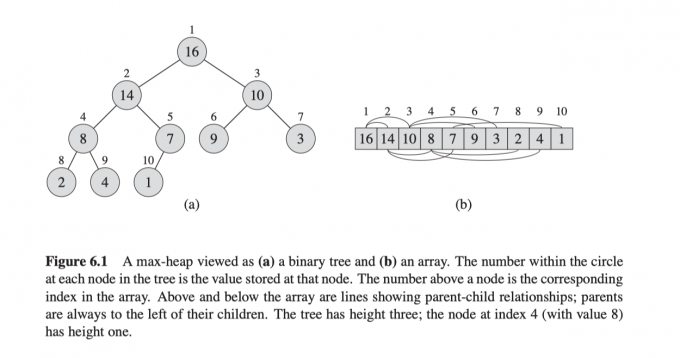
堆的数组$A$ 有两个属性:
$A.length$ :数组元素的个数,A[1..A.length]中都存有值。
$A.heap-size$ :有多少个堆元素在数组,A[1..heap-size]中存放的是堆的有效元素。
($0\leq A.heap-size\leq A.lengh$ )
堆的性质:
$A[1]$ :存放的是树的根结点。
对于给定的一个结点 $i$ ,很容易计算他的父结点、左孩子和右孩子的下标。
PARENT(i)
1
return i/2 //i>>>1
LEFT(i)
1
return 2*i //i<<<1
RIGHT(i)
1
return 2*i+1 //i<<<1 | 1
包含$n$ 个元素的堆的高度为 $\Theta(\lg{n})$
堆结构上的基本操作的运行时间至多和堆的高度成正比,即时间复杂度为 $O(\lg{n})$ .
叶子结点:n/2+1 , n/2+2 , … , n
堆的分类:
最大堆:
除了根以外的结点 $i$ 都满足 $A[\text{PARENT}(i)]\geq A[i]$ .
某个结点最多和其父结点一样大。
堆的最大元素存放在根结点中。
最小堆:
除了根以外的结点 $i$ 都满足 $A[\text{PARENT}(i)]\leq A[i]$ .
堆的最小元素存放在根结点中。
堆的基本过程 :
- MAX-HEAPIFY:维护最大堆的过程,时间复杂度为 $O(\lg{n})$
- BUILD-MAX-HEAP:将无序的输入数据数组构造一个最大堆,具有线性时间复杂度 $O(n\lg{n})$ 。
- HEAPSORT:对一个数组进行原址排序,时间复杂度为 $O(n\lg{n})$
- MAX-HEAP-INSERT、HEAP-EXTRACT-MAX、HEAP-INCREASE-KEY和HEAP-MAXIMUM:利用堆实现一个优先队列,时间复杂度为 $O(\lg{n})$ .
维护:MAX-HEAPIFY
调用MAX-HEAPIFY的时候,假定根结点LEFT(i)和RIGHT(i)的二叉树都是最大堆,但A[i]可能小于其左右孩子,因此违背了堆的性质。
MAX-HEAPIFY通过让 A[i]“逐级下降”,从而使下标为i的根结点的子树满足最大堆的性质。
MAX-HEAPIFY(A, i)
- 功能:维护下标为i的根结点的子树,使其满足最大堆的性质。
- 参数:i 是该子树的根结点,其左子树右子树均满足最大堆的性质。
1 | l = LEFT(i) |
下图是执行 MAX-HEAPIFY(A, 2)的执行过程。A.heap-size=10, 图(a)(b)(c)依次体现了值为4的结点依次下降的过程。
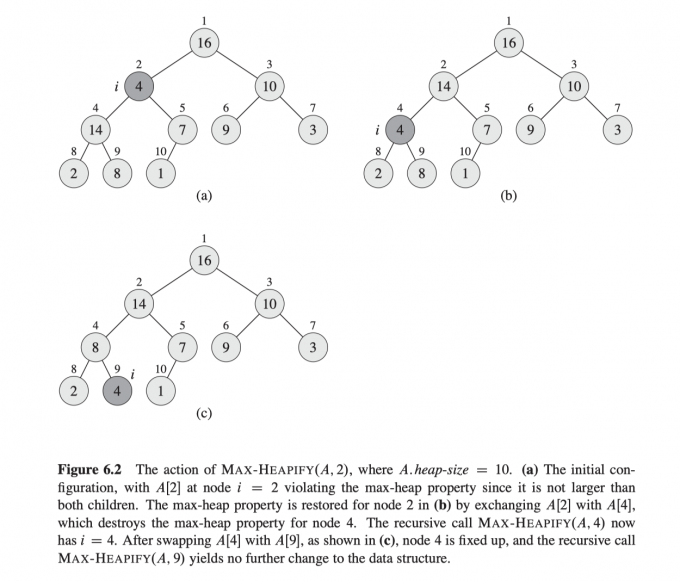
时间复杂度分析 :
MAX-HEAPIFY的时间复杂度为 $O(lg{n})$.
建堆:BUILD-MAX-HEAP
堆的性质:
子数组A[n/2+1..n]中的元素都是树的叶子结点。因为下标最大的父结点是n/2,所以n/2以后的结点都没有孩子。
建堆 :每个叶结点都可以看成只包含一个元素的堆,利用自底向上的方法,对树中其他结点都调用一次MAX-HEAPIFY,把一个大小为n = A.length的数组A[1..n]转换为最大堆。
BUILD-MAX-HEAP(A)
- 功能:把A[1..n]数组转换为最大堆
1 | A.heap-size = A.length |
下图是把A数组构造成最大堆的过程:
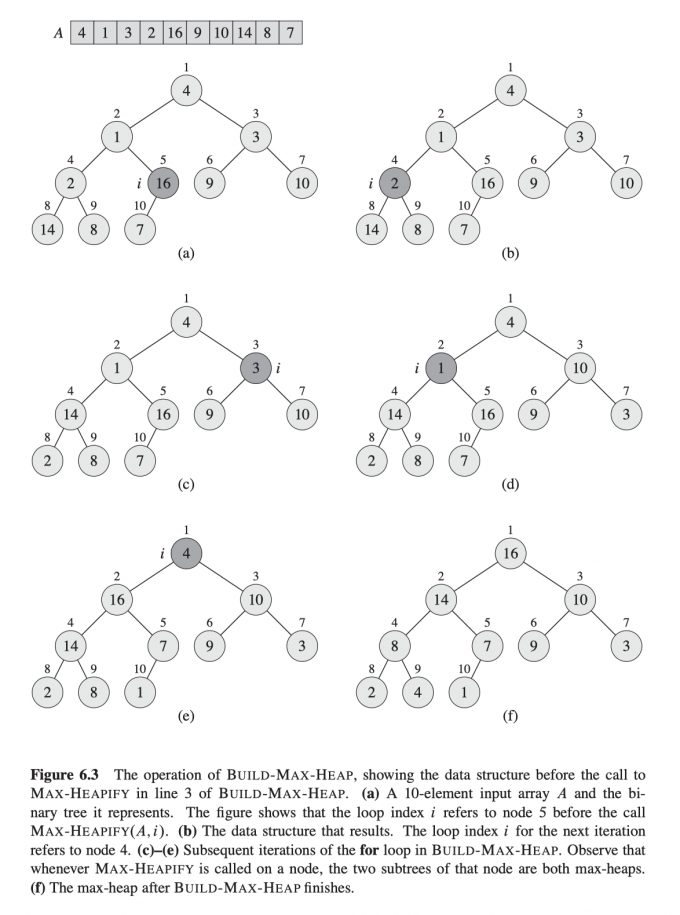
时间复杂度分析 :
BUILD-MAX-HEAP需要 $O(n)$ 次调用MAX-HEAPIFY,因此构造最大堆的时间复杂度是 $O(n\lg{n})$ .
排序:HEAPSORT
算法思路:
- 初始化时,调用BUILD-MAX-HEAP将输入数组A[1..n]建成最大堆,其中 n = A.length。
- 调用后,最大的元素在A[1],将A[1]和A[n]互换,可以把元素放在正确的位置。
- 将n结点从堆中去掉(通过减少A.heap-size实现),剩余结点中,原来根的孩子仍是最大堆,但根结点可能会违背堆的性质,调用MAX-HEAPIFY(A, 1),从而构造一个新的最大堆。
- 重复步骤3,直到堆的大小从n-1降为2.
HEAPSORT(A)
- 功能:利用堆对数组排序
1 | BUILD-MAX-HEAP(A) |
下图为调用HEAPSORT的过程图:
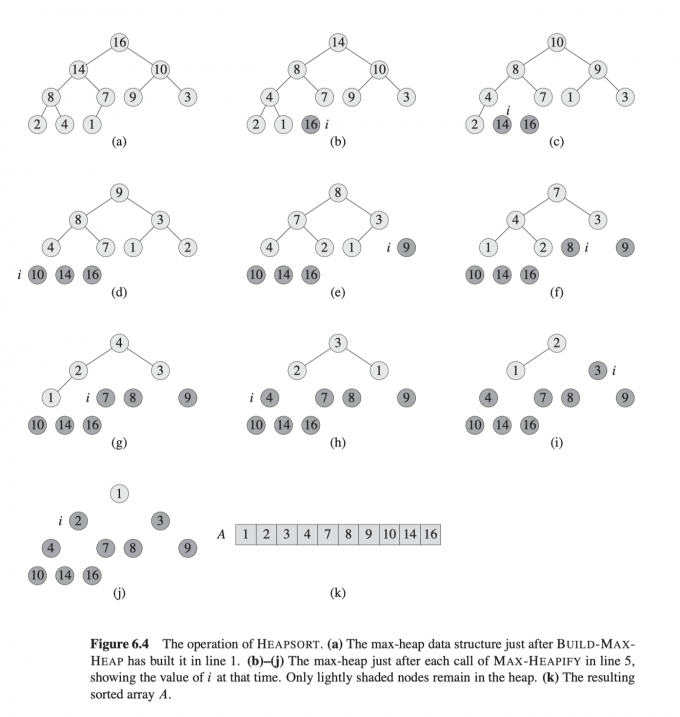
时间复杂度分析 :
建堆BUILD-MAX-HEAP的时间复杂度为 $O(n\lg{n})$ ,n-1次调用MAX-HEAPIFY的时间复杂度为 $O(n\lg{n})$ ,所以堆排序的时间复杂度为 $O(n\lg{n})$ .
堆的应用:优先队列
这里关注如何用最大堆实现最大优先队列。
优先队列(priority queue):
一种用来维护由一组元素构成的集合S的数据结构,其中每一个元素都有一个相关的值,称为关键字(key)。
(最大)优先队列支持的操作 :
- INSERT(S, x):把元素 $x$ 插入集合S中,时间复杂度为 $O(\lg{n})$ 。
- MAXIMUM(S):返回S中具有最大关键字的元素,时间复杂度为 $O(1)$ 。
- EXTRACT-MAX(S):去掉并返回S中的具有最大关键字的元素,时间复杂度为 $O(\lg{n})$ 。
- INCREASE-KEY(S, x, k):将元素 $x$ 的关键字值增加到k,这里假设k的大小不小于元素 $x$ 的原关键字值,时间复杂度为 $O(\lg{n})$ 。
MAXIMUM
将集合S已建立最大堆的前提下,调用HEAP-MAXIMUM在 $\Theta(1)$ 实现MAXIMUM的操作。
HEAP-MAXIMUM(A)
- 功能:实现最大优先队列MAXIMUM的操作,即返回集合中最大关键字的元素。
1 | return A[1] |
时间复杂度分析 :$\Theta(1)$
EXTRACT-MAX
类似于HEAPSORT的过程。
A[1]为最大的元素,A[1]的孩子都是最大堆。
将A[1]和A[heap-size]交换,减少堆的大小(heap-size)。
此时根结点的孩子满足最大堆,而根不一定满足最大堆性质,维护一下当前堆。
HEAP-EXTRACT-MAX(A)
- 功能:实现最大优先队列EXTRACT-MAX的操作,即去掉并返回集合中最大关键字的元素。
1 | if A.heap-size < 1 |
时间复杂度分析 :$O(\lg{n})$ .
INCREASE-KEY
如果增加A[i]的关键词,可能会违反最大堆的性质,所以实现HEAP-INCREASE-KEY的过程类似插入排序:从当前i结点到根结点的路径上为新增的关键词寻找恰当的插入位置。
当前元素不断和其父结点比较,如果当前元素的关键字更大,则和父结点进行交换。
步骤1不断重复,直至当前元素的关键字比父结点小。
HEAP-INCREASE-KEY(A, i, key)
- 功能:实现最大优先队列INCREASE-KEY的功能,即将A[i]的关键字值增加为key.
- 参数:i为待增加元素的下标,key为新关键字值。
1 | if key < A[i] |
下图展示了HEAP-INCREASE-KEY的过程:
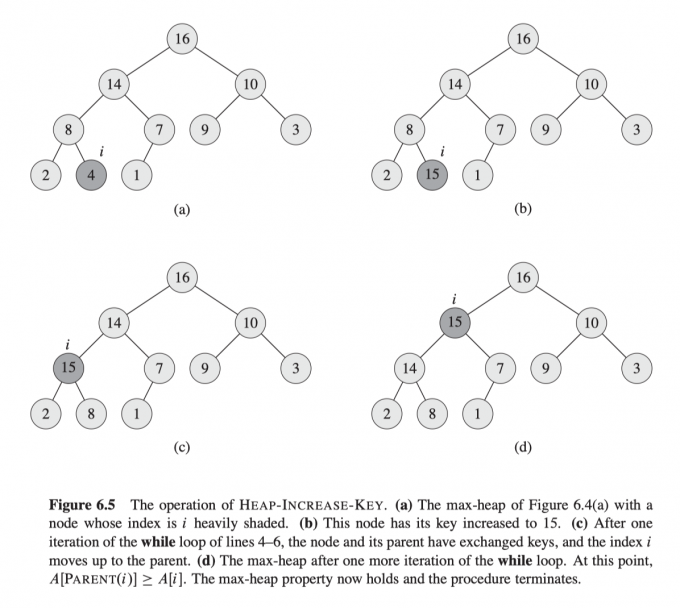
时间复杂度分析 :$O(\lg{n})$
INSERT
如何插入一个元素扩展最大堆?
- 先通过增加一个关键字值为 $-\infin$ 的叶子结点扩展最大堆。
- 再调用HEAP-INCREASE-KEY过程为新的结点设置对应的关键字值。
MAX-HEAP-INSERT(A, key)
- 功能:实现最大优先队列的INSERT功能,即将关键字值为key的新元素插入到最大堆中。
- 参数:key是待插入元素的关键字值。
1 | A.heap-size = A.heap-size + 1 |
时间复杂度分析 :$O(\lg{n})$ .
快速排序
对于包含 $n$个数的输入数组来说,快速排序是一个最坏情况时间复杂度为 $\Theta(n^2)$ 的排序算法。
虽然最坏情况时间复杂度很差,但是快速排序通常是实际排序应用中最好的选择,因为他的平均性能非常好:他的期望时间复杂度为 $\Theta(n\lg{n})$ ,而且 $\Theta(n\lg{n})$ 中隐含的常数因子非常小。
另外,它还能进行原址排序。
分治
对A[p..r]子数组进行快速排序的分治过程:
分解:
数组A[p..r]被划分为两个(可能为空)的子数组A[p..q-1]和A[q+1..r]。
使得A[p..q-1]中的每个元素都小于等于A[q],A[q+1..r]中的每个元素都大于等于A[q]。
其中计算下标q也是分解过程的一部分。
解决:通过递归调用快速排序,对子数组A[p..q-1]和A[q+1..r]进行排序。
合并:因为子数组都是原址排序的,所以不需要合并操作,A[p..r]已经排好序。
快速排序:QUICKSORT
按照分治的过程。
QUICKSORT(A, p, r)
- 功能:快速排序子数组A[p..r]
1 | if p < r |
数组的划分:PARTITION
快速排序的关键部分就在于如何对数组A[p..r]进行划分,即找到位置q。
PARTITION(A, p, r)
- 功能:对子数组A[p..r] 划分为两个子数组A[p..q-1]和子数组A[q+1..r],其中A[p..q-1] 小于等于A[q]小于等于A[q+1..r]
- 返回:数组的划分下标q
1 | x = A[r] |
PARTITION总是选择一个 $x=A[r]$ 作为主元(pivot element),并围绕它来划分子数组A[p..r]。
在循环中,数组被划分为下图四个(可能为空的)区域:
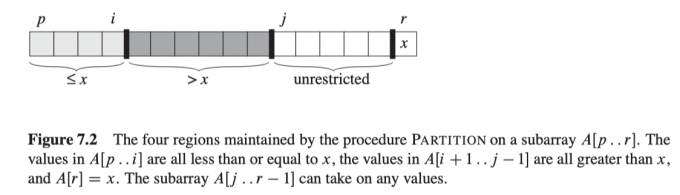
- $p\leq k\leq i$ ,则 $A[k]\leq x$ .
- $i+1\leq k \leq j-1$ ,则 $A[k]>x$.
- $k = r$ ,则 $A[k]=x$ .
- $j\leq k\leq r-1$ ,则 $A[k]$ 与 $x$ 无关。
下图是将样例数组PARTITION的过程:

快速排序的性能
[*]待补充
快速排序的随机化版本
与始终采用 $A[r]$ 作为主元的方法不同,随机抽样是从子数组A[p..r]随机选择一个元素作为主元。
加入随机抽样,在平均情况下,对子数组A[p..r]的划分是比较均匀的。
RANDOMIZED-PEARTITION(A, p, r)
- 功能:数组划分PARTITION的随机化主元版本
1 | i = RANDOM(p, r) |
RANDOMIZED-QUICKSORT(A, p, r)
- 功能:使用随机化主元的快速排序
1 | if p < r |
计数排序
计数排序 :
假设 $n$ 个输入元素中的每一个都是在 0到 $k$ 区间内到一个整数,其中 $k$ 为某个整数。当 $k = O(n)$ 时,排序的运行时间为 $\Theta(n)$ .
计数排序的思想 :
对每一个输入元素 $x$,确定小于 $x$ 的元素个数。利用这个信息,就可以直接把 $x$ 放在输出数组正确的位置了。
COUNTING-SORT(A, B, k)
- 功能:计数排序
- 参数:
- A[1..n]输入的待排序数组,A.length = n
- B[1..n] 存放排序后的输出数组;
- 临时存储空间 C[0..k] ,A[1..n]中的元素大小不大于k.
1 | let C[0..k] be a new array |
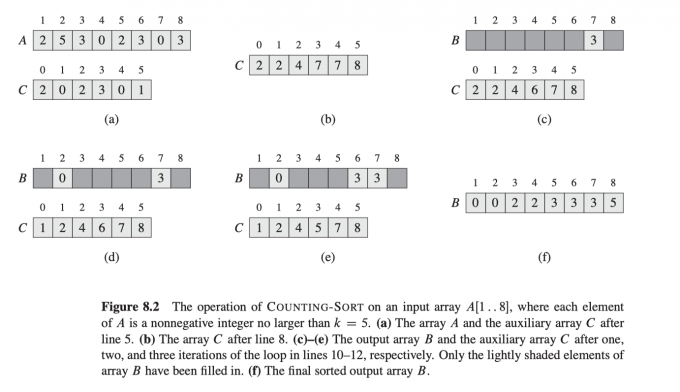
下图是计数排序的过程:
Reference
- Introduction to Algorithms.
- 算法导论
「算法导论」:排序-总结

