「机器学习-李宏毅」:Unsupervised Learning:Word Embedding
这篇文章主要是介绍一种无监督学习——Word Embedding(词嵌入)。
文章开篇介绍了word编码的1-of-N encoding方式和word class方式,但这两种方式得到的单词向量表示都不能很好表达单词的语义和单词之间的语义联系。
Word Embedding可以很好的解决这个问题。
Word Embedding有count based和prediction based两种方法。文章主要介绍了prediction based的方法,包括如何predict the word vector? 为什么这样的模型works?介绍了prediction based的变体;详细阐述了该模型中sharing parameters的做法和其必要性。
文章最后简单列举了word embedding的相关应用,包括multi-lingual embedding, multi-domain embedding, document embedding 等。
Word to Vector
如何把word转换为vector?
1-of-N Encoding
第一种方法是1-of-N Encoding:
Vector的维度是单词总数,每一维度都代表一个单词。

1-of-N Encoding的方法简单,但这种向量的表示方式not imformative,即向量表示不能体现单词之间的语义关系。
Word Class
对1-of-N Encoding方式改进,Word Class采用聚类cluster的方式,根据类别训练一个分类器。
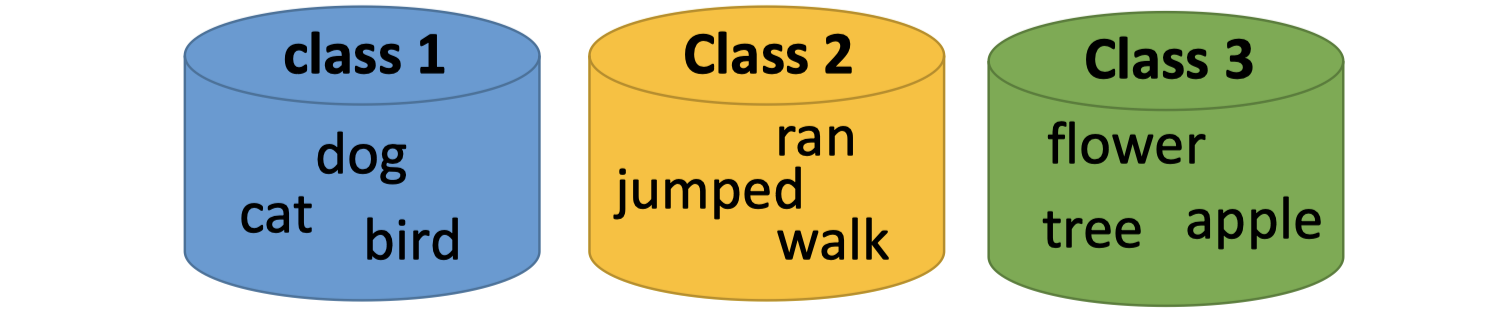
但这种人为分类的方式,信息是会部分丢失的,即光做clustering是不够的,会丢失单词的部分信息。
Word Embedding
第三种方式是Word Embedding。(词嵌入)
Word Embedding: Machine learns the meaning of words from reading a lot of documents without supervision.
Word Embedding,机器通过阅读大量文章学习单词的含义,用vector的形式表示单词的语义。训练时只需要给机器大量文章,不需要label,因此是无监督学习。
Word Embedding
如何做Word Embedding呢?
auto-encoder?
能否用auto-encoder的方式来做词嵌入呢?
即用1-of-N encoding的方式对单词编码,作为训练的输入和输出。
word2vec时,把model中的某一hidden layer的输出作为该单词的向量表示。
这种方式是不可以的,不可以用auto-encoder。因为auto-encoder不能学到informative的信息,即用auto-encoder表示的向量不能表达word的语义。
Exploit the Context
A word can be understood by its context.
所以Word Embedding可以利用上下文来学习word的语义。
如何利用单词的上下文来学习呢?
Count based
如果两个单词 $w_i$ 和 $w_j$ 在文章中经常同时出现,那么 $V(w_i)$ ( $w_i$ 的向量表示)和 $V(w_j)$ 的向量表示会很close.
E.g. Glove Vector: https://nlp.stanford.edu/projects/glove/
GloVe的表示法有两个亮点:
Nearest neighbors:vectors之间的欧几里得距离(或者余弦相似度)能较好表示words之间的语义相似度。
Linear substructures:用GloVe方法表示的vectors有有趣的线性子结构。
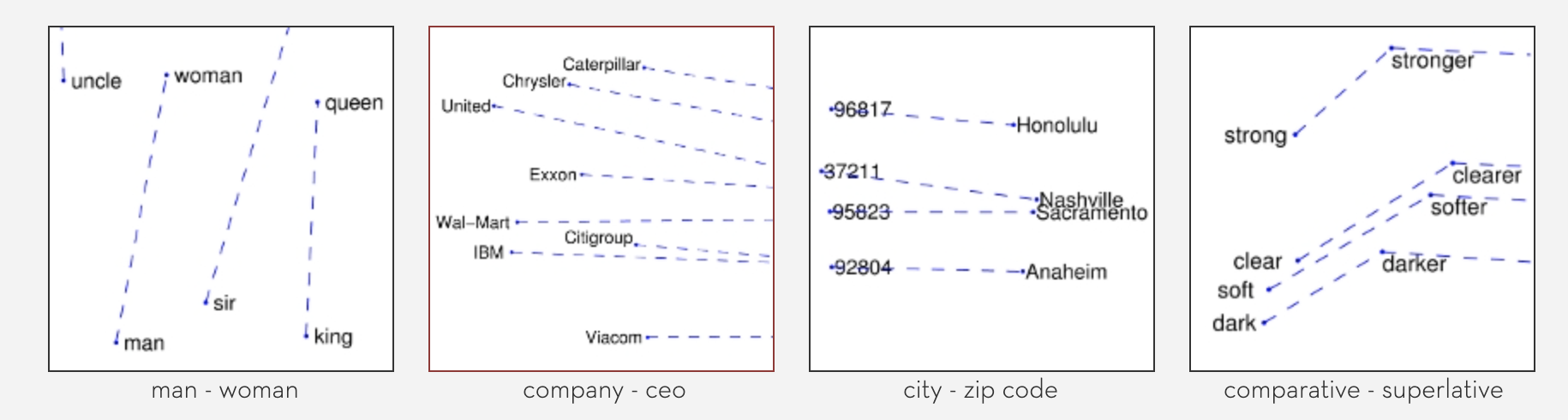
Prediction based
使用预测的方式来表示。
Prediction based
How to predict?
prediction based的方法是用前一个单词来预测当前单词。
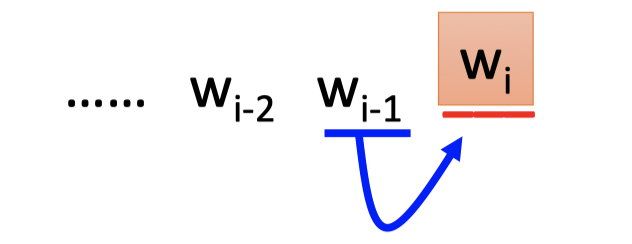
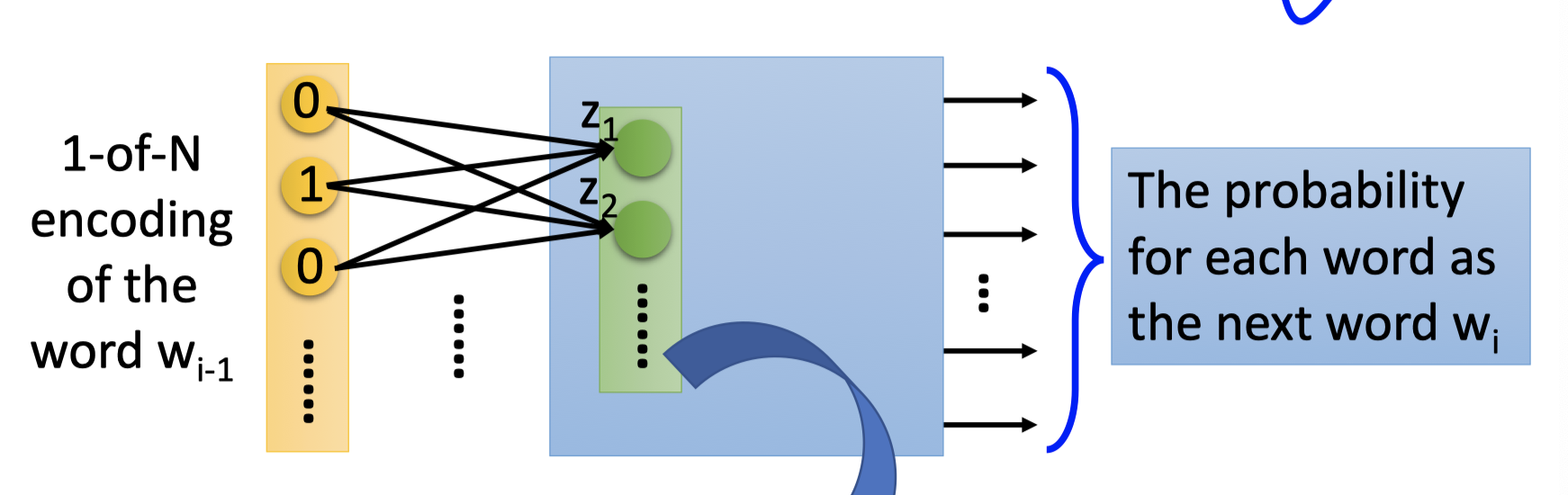
训练时: $w_{i-1}$ 的1-of-N encoding编码作为输入,$w_i$ 的1-of-N encoding的编码作为输出。
NN如上图,$w_{i-1}$ 的1-of-N encoding编码作为输入,输出的vector表示下一个单词是 $w_i$ 的概率。
word2vec : $w_{i-1}$ 的1-of-N encoding编码作为NN的输入,$w_i$ 的向量表示为第一个hidden layer的neurons的输入 $z$ 。
Why it works?
直觉的解释他为什么能work。
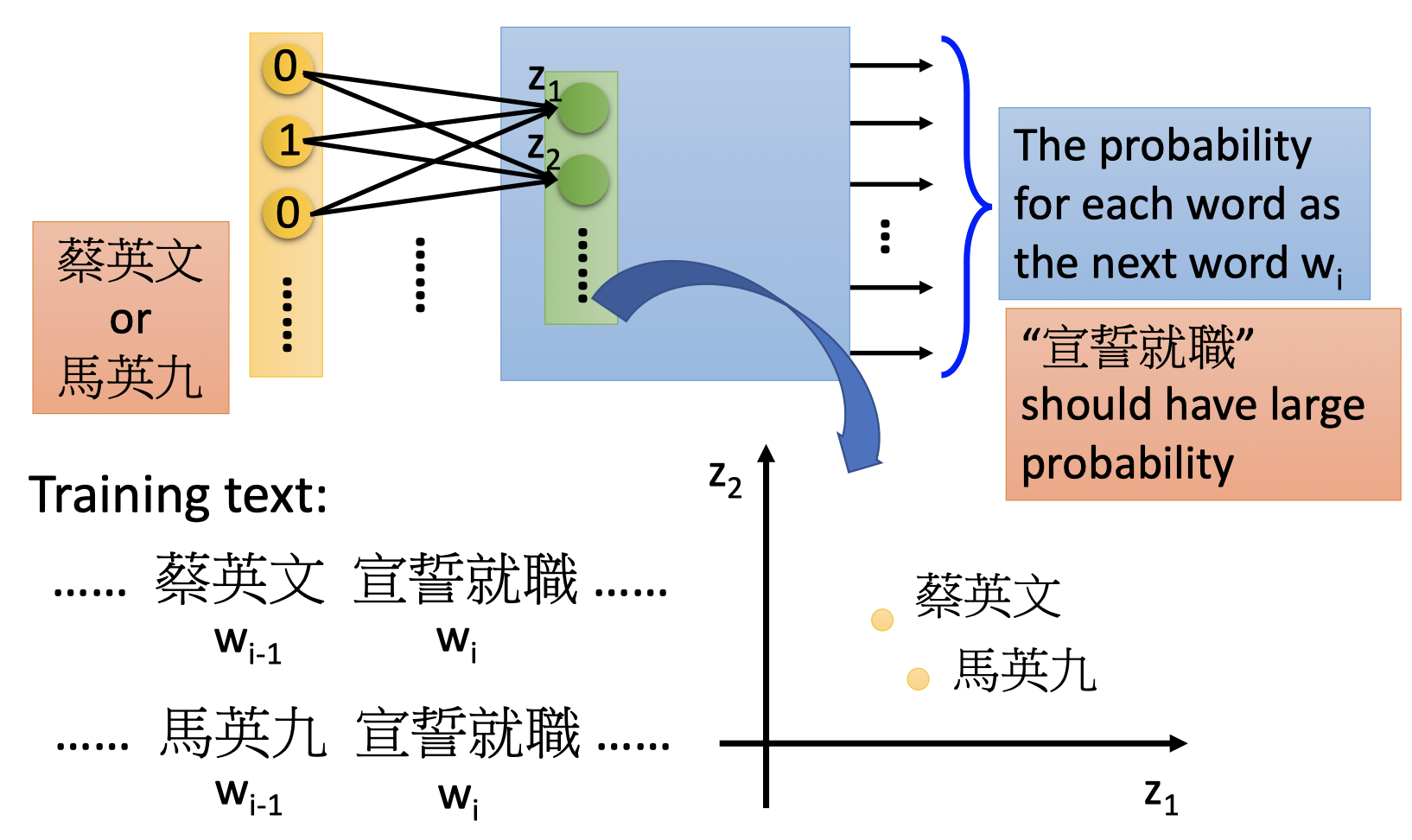
如上图,蔡英文 宣誓就职 和 马英九 宣誓就职,虽然 $w_{i-1}$ 不同,但NN的输出中,“宣誓就职”的概率应该最大。
即hidden layers必须把不同的 $w_{i-1}$ project到相同的space,要求hidden layer的input是相近的,NN的输出才是相近的。
Prediction-based :Various Architecture
因为一个单词的下一个单词范围非常大,所以使用前一个单词预测当前单词的方法,performance是较差的。
因此常常会使用多个单词来预测下一个单词,NN的输入是多个单词连接在一起组成的向量,一般NN的输入至少为10个单词,word embedding的performance较好。
除了使用多个单词的方法,prediction-based的方法还用两种变体结构。
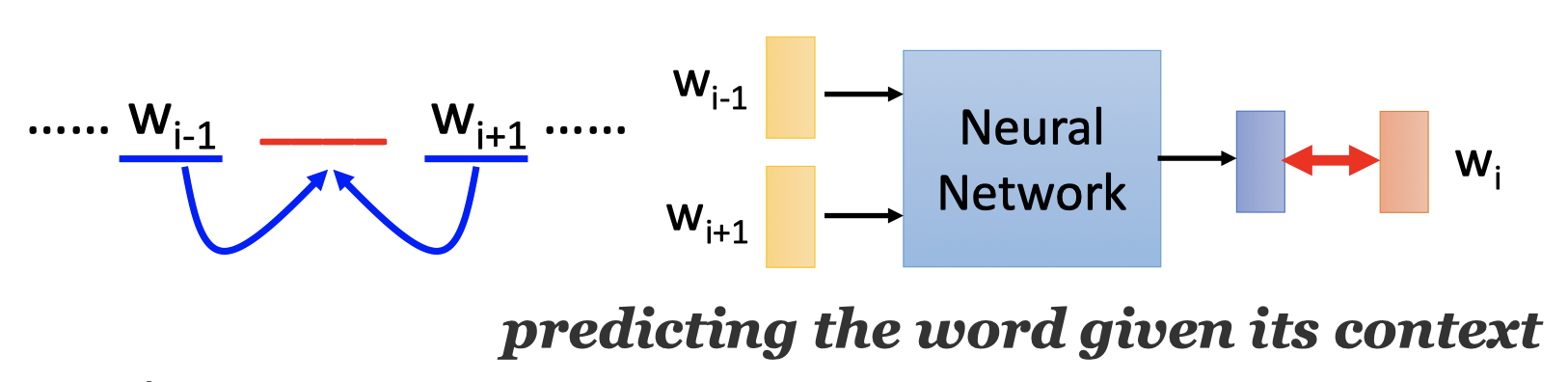
Continuous bag of word (CBOW) model: predicting the word given its context.
使用单词的前后文(前一个单词和后一个单词)来预测当前单词。
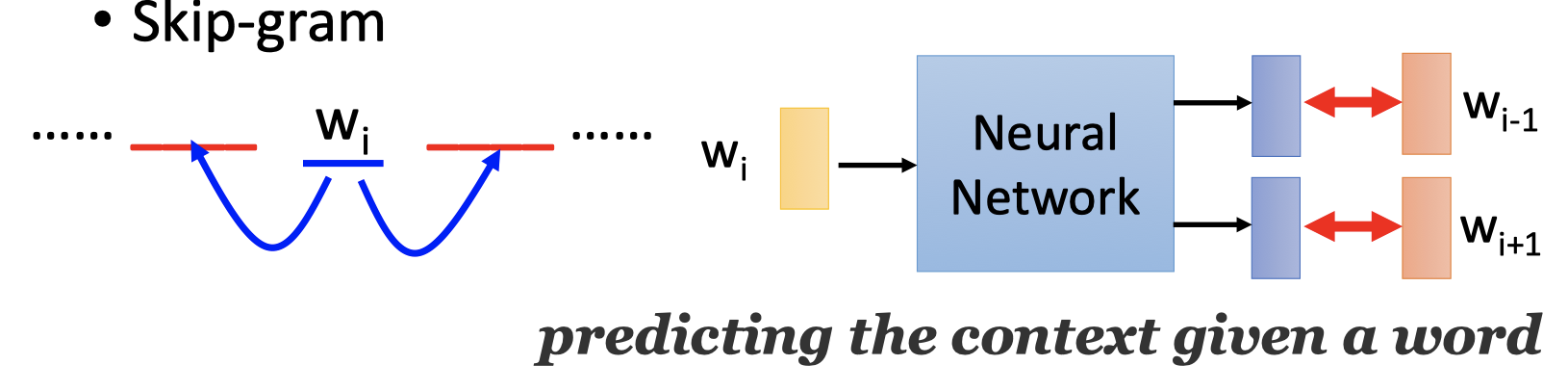
Skip-gram: predicting the context given a word.
使用中间单词来预测单词的前一个单词和后一个单词。
Sharing Parameters
使用多个单词作为NN的输入,提高了word embedding的performance,但也大幅增加了模型训练的参数数量。
使用sharing parameters(共享参数)能大量减少模型的参数数量。
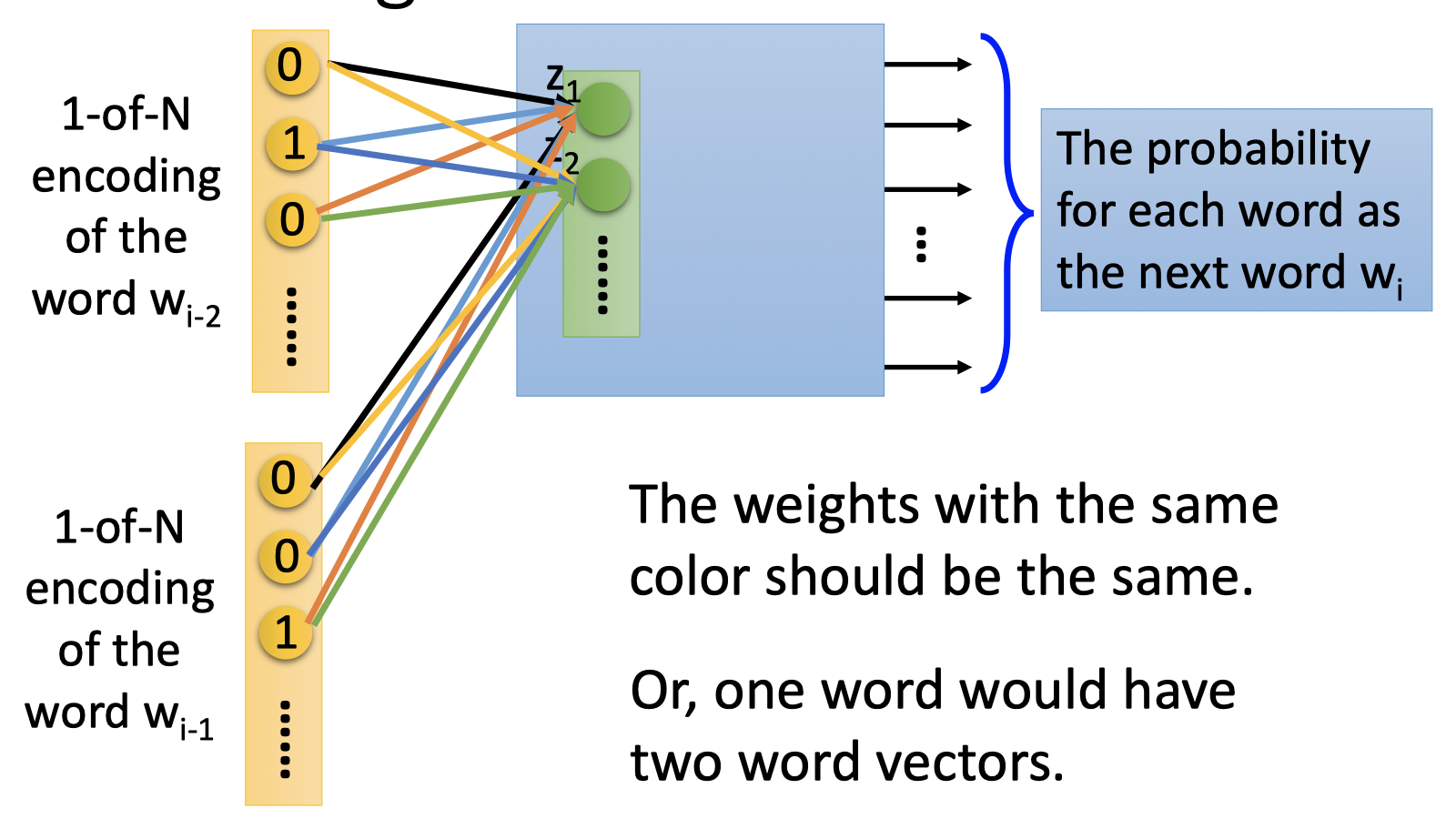
如上图,输入单词连接到neurons的权重应该是相同的。
除了能减少参数,sharing parameters也是必要的。否则,如果NN的输入的单词顺序交换,那么得到的单词向量是不同的。
How to train sharing parameters?
假设两个单词相同维度连接到neuron的weight是 $w_i,w_j$ ,在训练中,如何让 $w_i=w_j$ ?
Given the same initialization.(相同的初始化)
原来的参数更新:
$$
w_i \longleftarrow w_i - \frac{\partial C}{\partial w_i} \
w_j \longleftarrow w_j - \frac{\partial C}{\partial w_j}
$$
虽然有相同的初始化,但在Backpropagation求偏微分时,$\frac{\partial C}{\partial w_i}$ 和 $\frac{\partial C}{\partial w_j}$ 不一样,那么参数 $w_i$ 和 $w_j$ 更新一次后就不同了。在训练sharing parameters的参数更新:
$$
w_i \longleftarrow w_i - \frac{\partial C}{\partial w_i} -\frac{\partial C}{\partial w_j}\
w_j \longleftarrow w_j - \frac{\partial C}{\partial w_j}-\frac{\partial C}{\partial w_i}
$$
这样更新后,$w_i$ 和 $w_j$ 仍保持一致。如果有多个单词,亦然。
Word2Vec
在word2vec时,根据sharing parameters的性质,计算单词的向量表示时,可以简化运算。
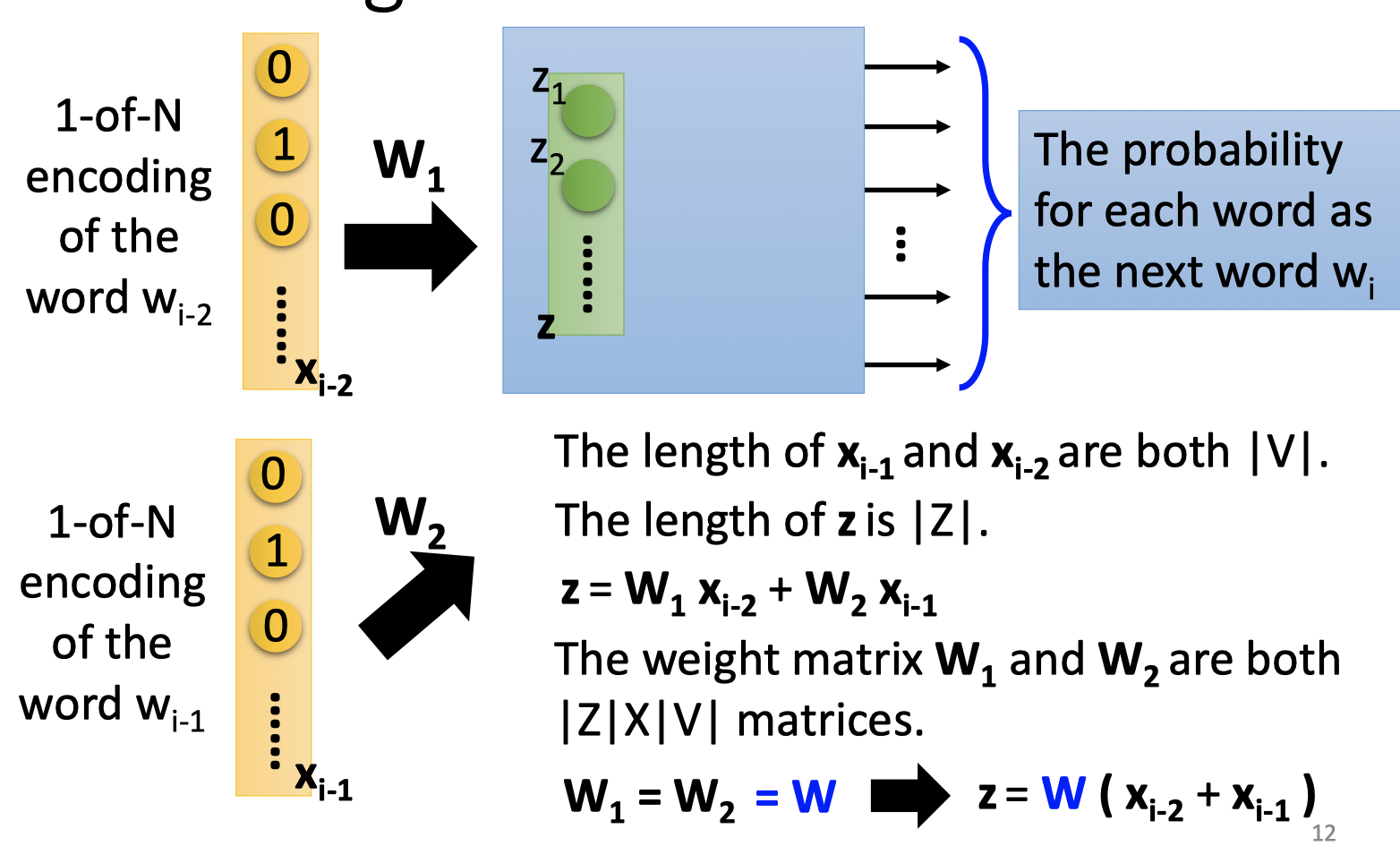
如上图,用前文单词 $x_{i-1},x_{i-2}$ 表示单词 $x_i$ 的向量表示 $z=W_1x_{i-2}+W_2x_{i-1}=W(x_{i-2}+x_{i-1})$ .
其中 $x_{i-1},x_{i-2}$ 的维度是|V|,$x_i$ 的向量表示 $z$ 的维度是 |Z|,$W_1=W_2=W$ 的维度为|Z|*|V|。
Advantages of Word Embedding
Word Embedding能得到一些有趣的特性。
向量之间有趣的线性子结构
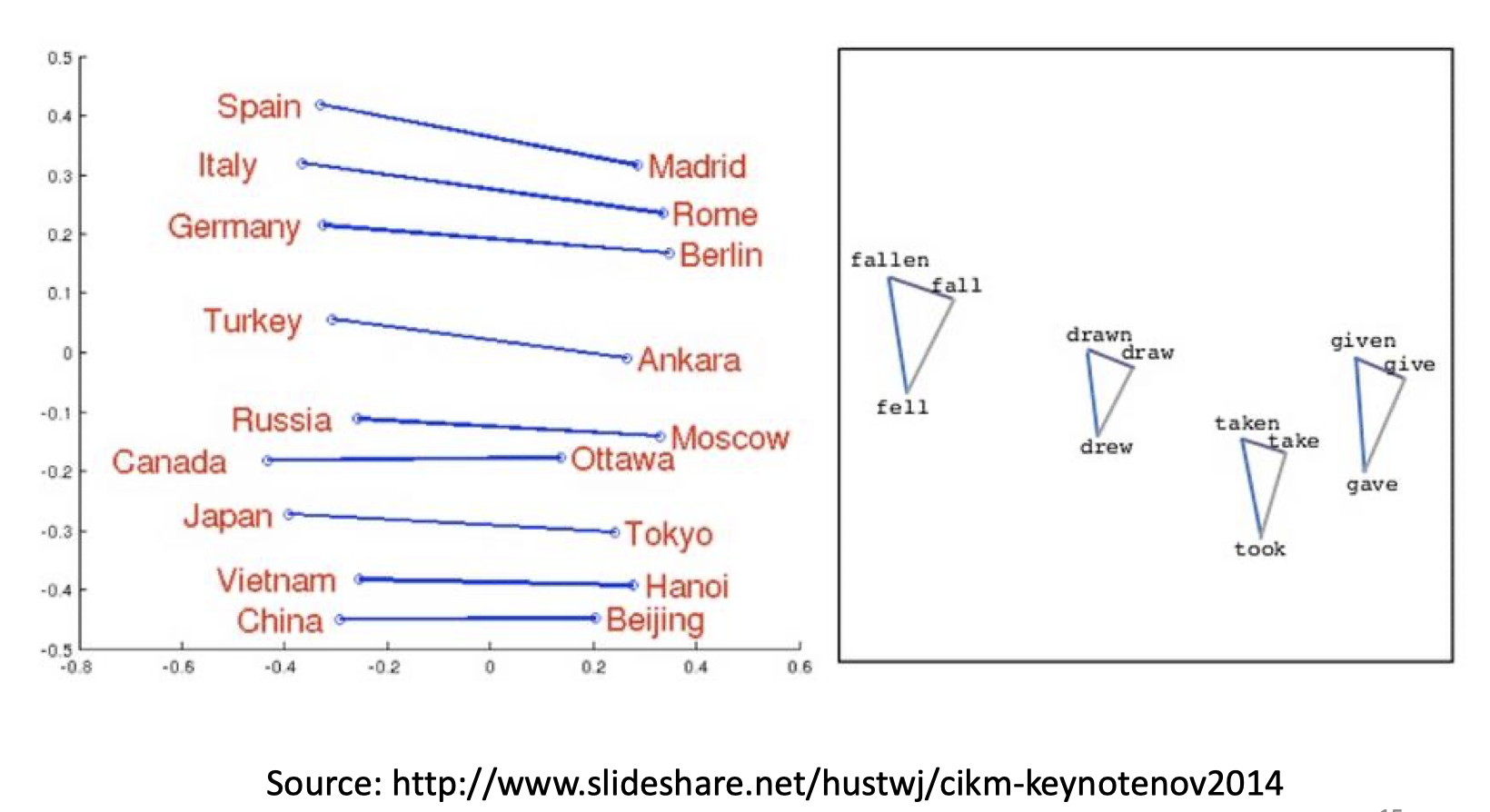
相近的向量有相近的语义
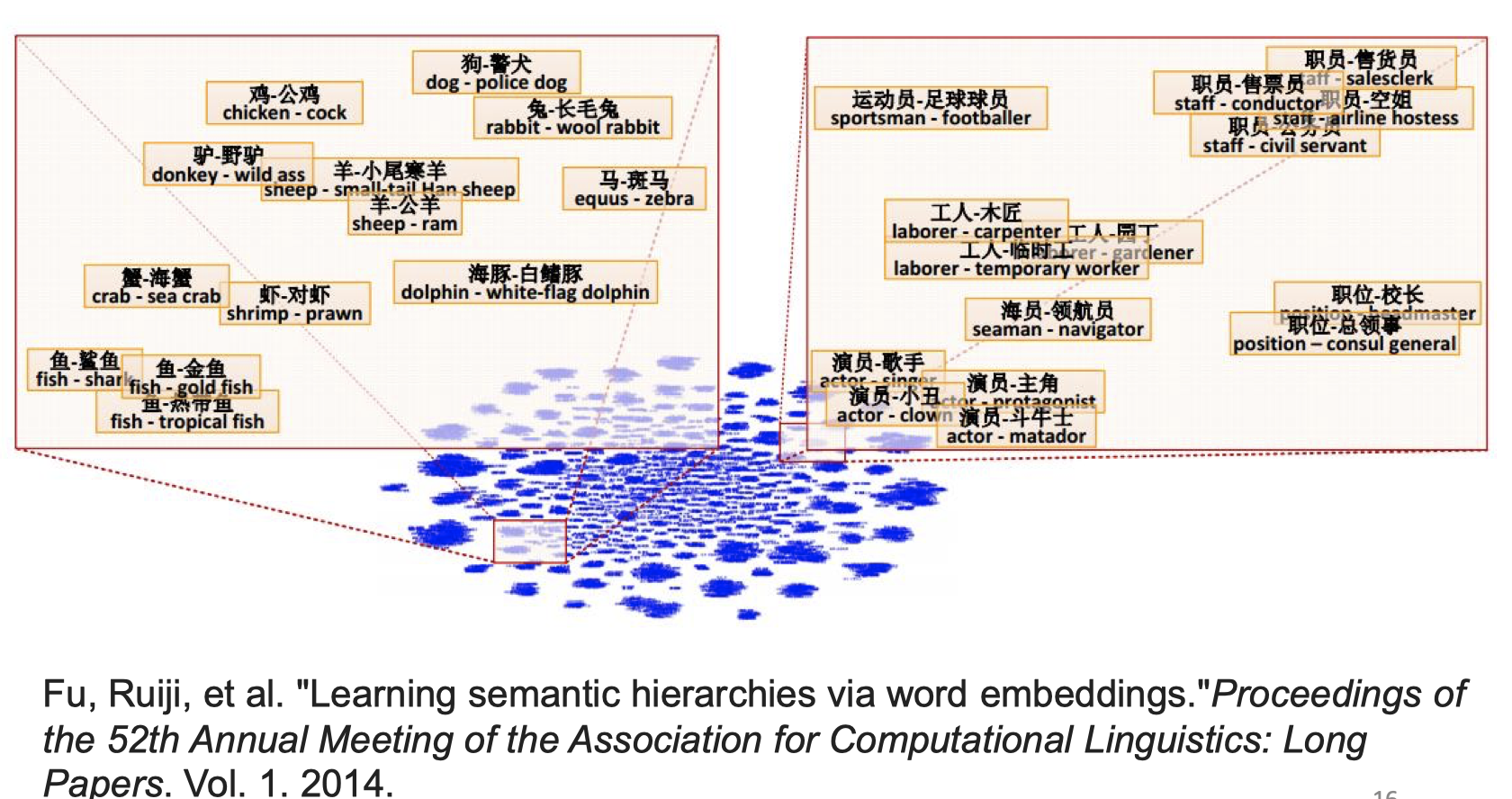
向量之间表示的语义特性

其他应用
Multi-lingual Embedding:实现翻译
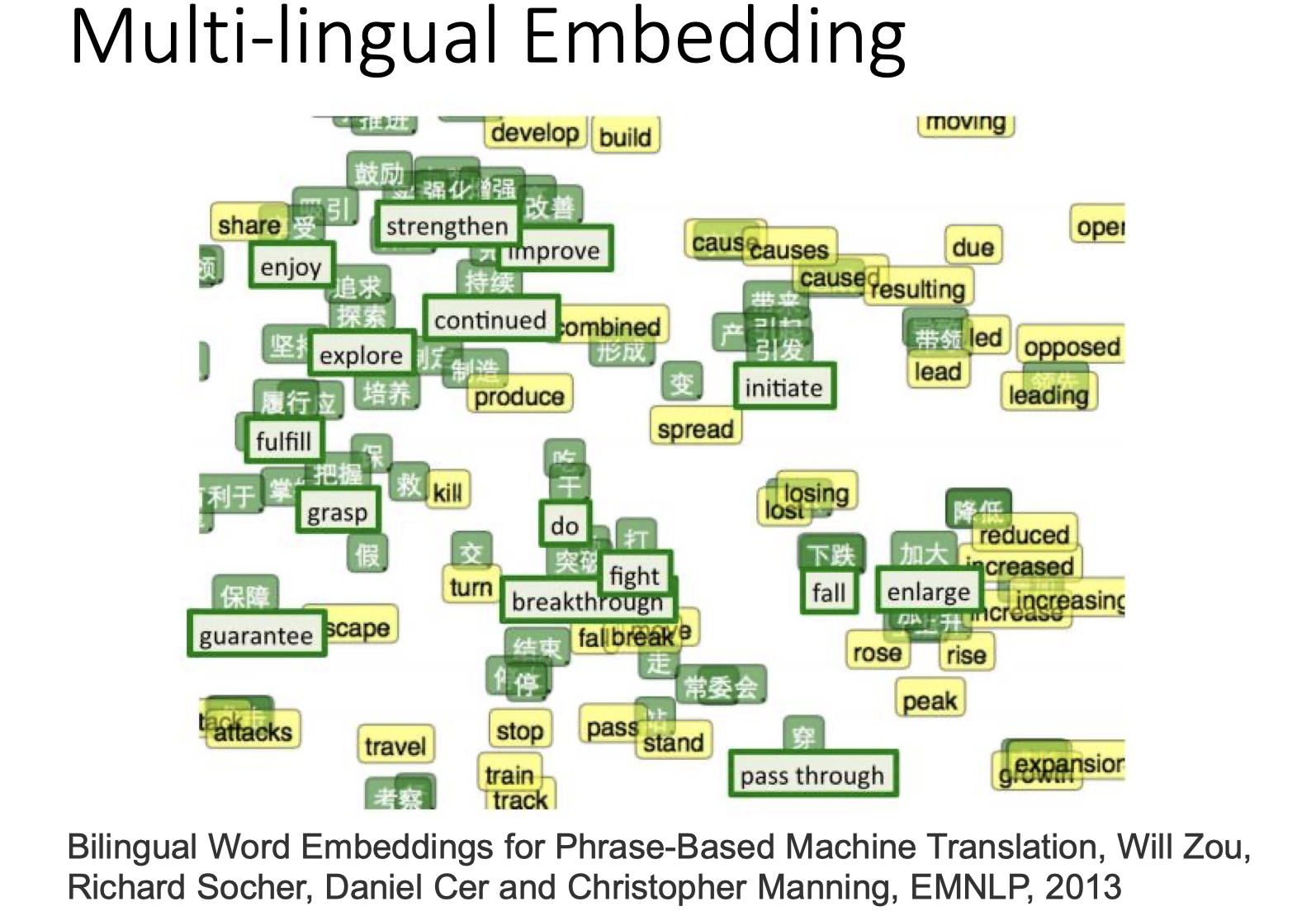
不同语言之间分开训练,训练出的不同语言所对应词汇的向量表示肯定不同,再将对应词汇的向量project到同一点,即实现了翻译。
Multi-domain Embedding
还可以做影像嵌入。
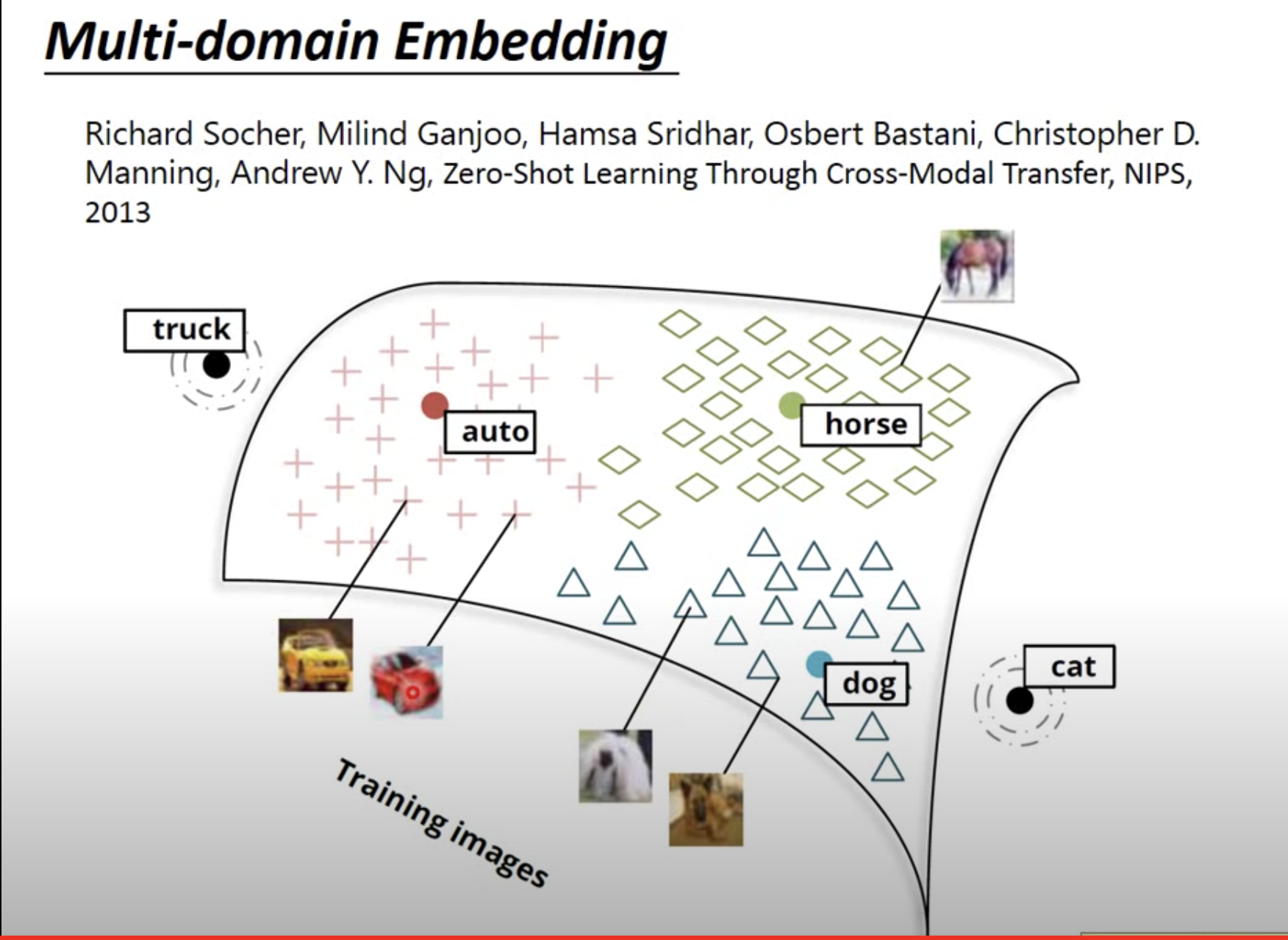
Document Embedding:将文件表示为一个向量
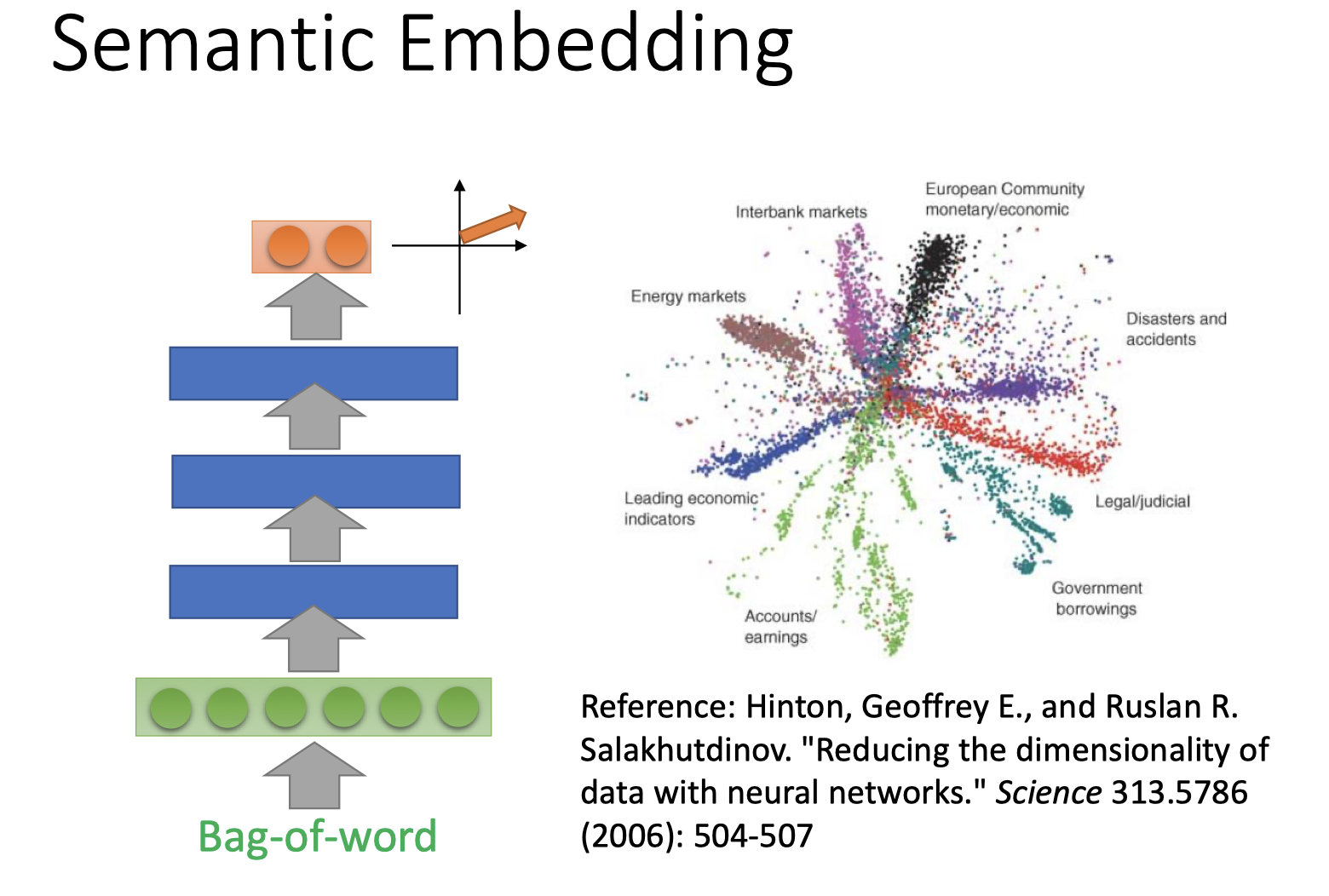
Bag of Word:
用Bag-of-word的方式编码文件,再实现semantic embedding。得到的文件表示向量可以表示文件的语义主题。
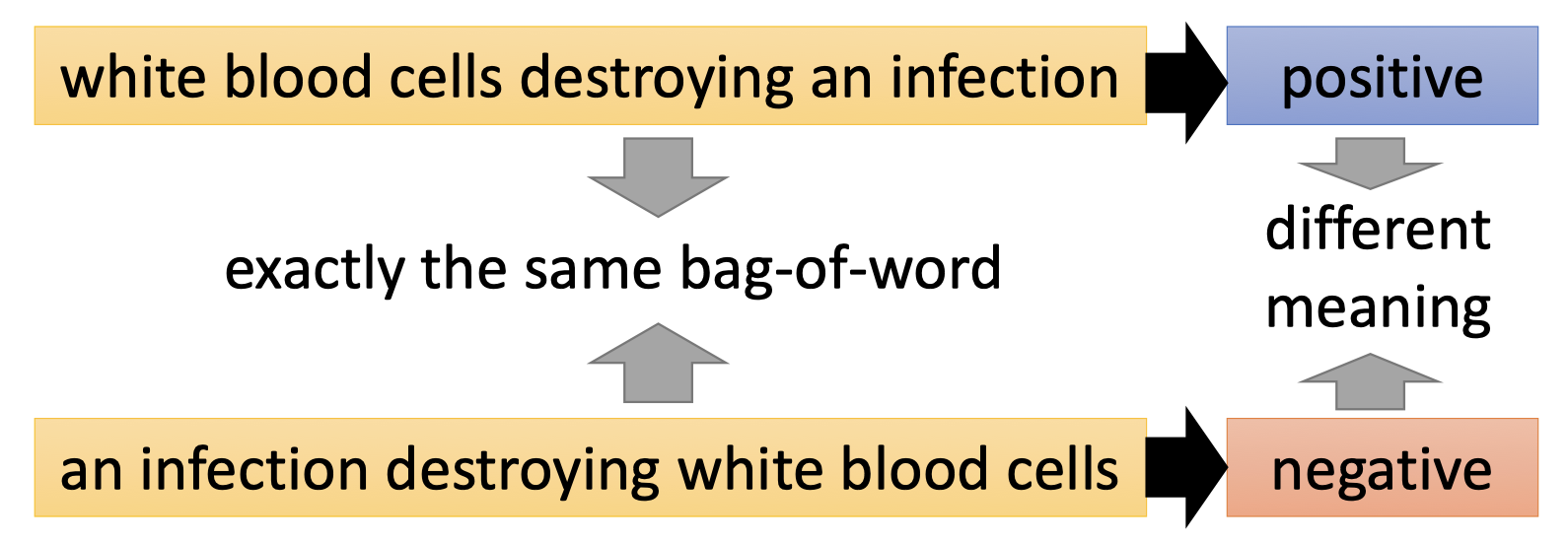
Beyond Bag of Word:
句子中单词的顺序也很大程度影响句子的语义。
因此,下图的两句话有相同的bag-of-word,但表达的含义完全相反。
关于beyond bag of word的相关工作参考reference 2.
Reference
beyond bag of word:

「机器学习-李宏毅」:Unsupervised Learning:Word Embedding
https://f7ed.com/2020/10/11/unsupervised-learning-word-embedding/

